Weight Initialization for Deep Learning Neural Networks

Senior AI Engineer | Building & Telling Stories about AI/ML Systems | Software Engineer
Introduction
Have you had a hard time training your model? Is your model not learning the complexities of your data?
I really understand you?
Do you know that weight initialization is a critical step for your model?
It's a way to deal with vanishing and exploding gradients problems that have haunted neural networks for decades
Do you want to learn more about?
Well, in this article, I will dig into these mysteries and discover effective initialization techniques.
And remember, if you like this article, share it with others ♻️
Understanding Vanishing and Exploding Gradients
The Core Problem
Backpropagation and Gradient Descent: These core algorithms compute the error gradient and update parameters in a neural network.
However, they often encounter two major hurdles: vanishing and exploding gradients.
Vanishing Gradients: In this scenario, gradients become increasingly smaller as the algorithm works through lower layers, leaving the weights virtually unchanged and stalling the learning process.
Exploding Gradients: Conversely, gradients may grow exponentially, leading to disproportionately large updates and causing the learning process to diverge. This issue is particularly prevalent in recurrent neural networks.
Historical Context and Empirical Observations
The challenges of unstable gradients in deep neural networks have been acknowledged for many years, contributing to the initial abandonment of deep learning techniques.
Breakthrough in Understanding: Around 2010, significant progress was made, particularly through the work of Xavier Glorot and Yoshua Bengio.
Their findings linked the vanishing gradients problem to the combination of sigmoid activation functions and certain weight initialization methods.
Xavier/Glorot and He Initialization: A New Era
The Xavier/Glorot and Bengio Proposal
To maintain a proper flow of signals (both forward and backward), Xavier/Glorot and Bengio suggested that the variance of a layer's outputs and inputs should be equal.
The Compromise Solution
Although ideal balance is impossible for layers with different numbers of inputs and neurons, their proposed initialization method offers an effective compromise.
Implementing Initialization
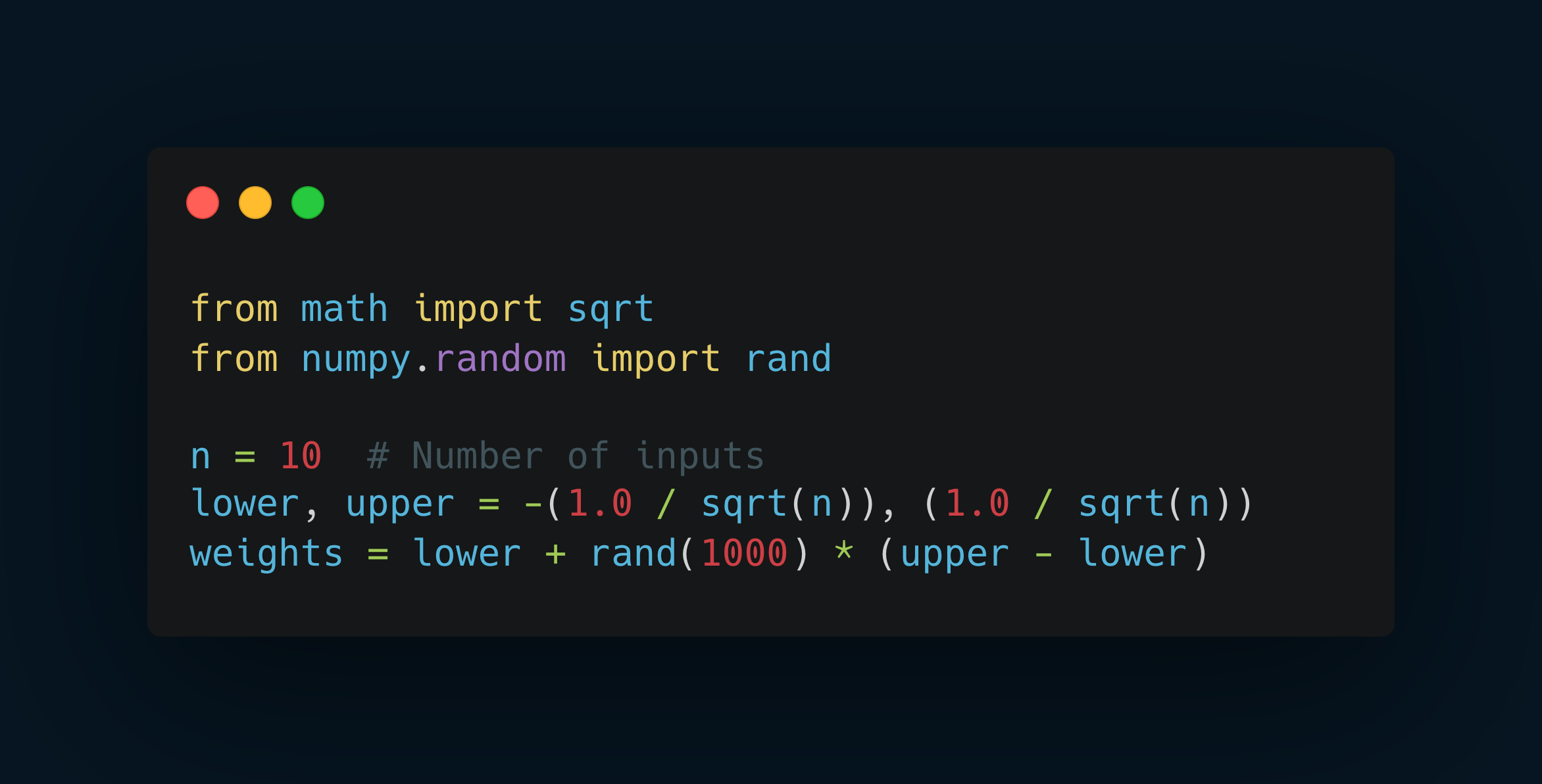
Xavier/Glorot Initialization: Focuses on maintaining variance balance by using an initialization strategy based on the number of inputs (fan-in) and outputs (fan-out) in a layer.
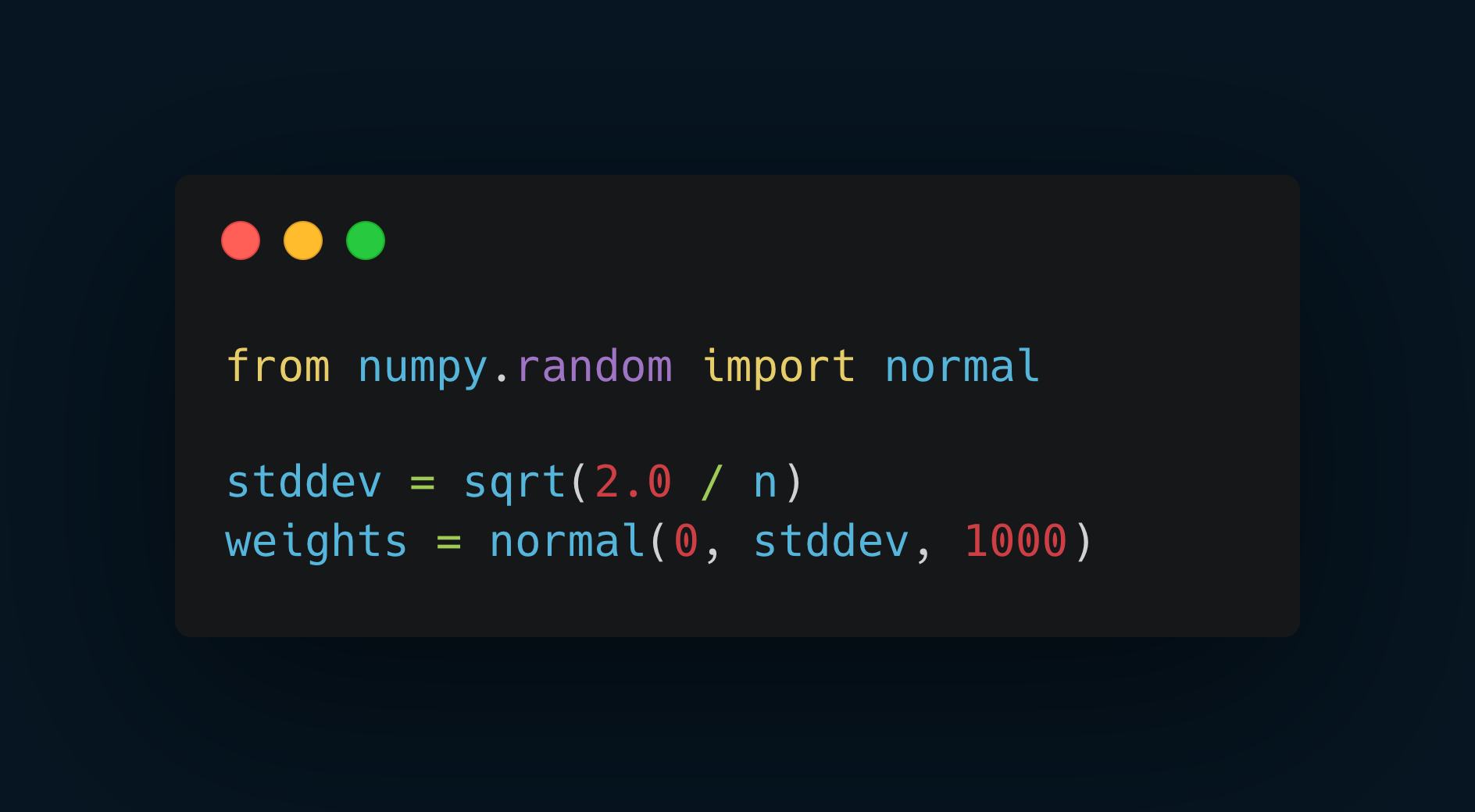
He Initialization: Tailored for ReLU and its variants, this method modifies the variance scaling according to the activation function used, providing a more robust solution for deep networks with ReLU activations.
Integration with Modern Techniques
Beyond Just Initialization
Different activation functions have varying requirements.
Adjusting weight initialization strategies according to the activation function used is crucial for effective learning.
Practical Python Examples
Xavier/Glorot Initialization Example:
He Initialization Example:
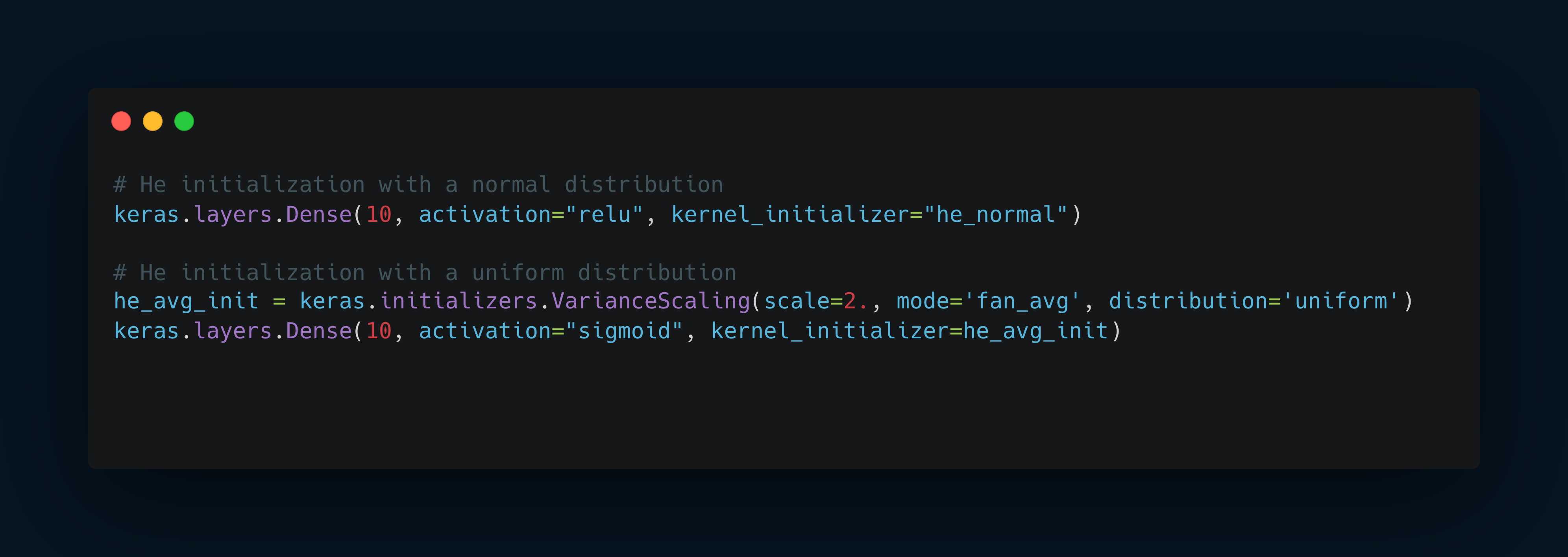
Keras implementation
By default, Keras uses Glorot initialization with a uniform distribution.
You can change this to He initialization by setting kernel_initializer="he_uniform" or ker nel_initializer="he_normal" when creating a layer, like this:
Pytorch implementation
PyTorch uses different default weight initialization methods depending on the type of layer:
Linear Layers (nn.Linear): The default initialization in linear layers (fully connected layers) uses an initialization is similar to the Xavier initialization method.
Convolutional Layers (nn.Conv2d, nn.Conv3d, etc.): For convolutional layers, PyTorch uses Kaiming (He) initialization by default.
Recurrent Neural Network Layers (nn.RNN, nn.LSTM, nn.GRU, etc.): In recurrent layers, the weights are initialized uniformly. The biases are typically set to zero.
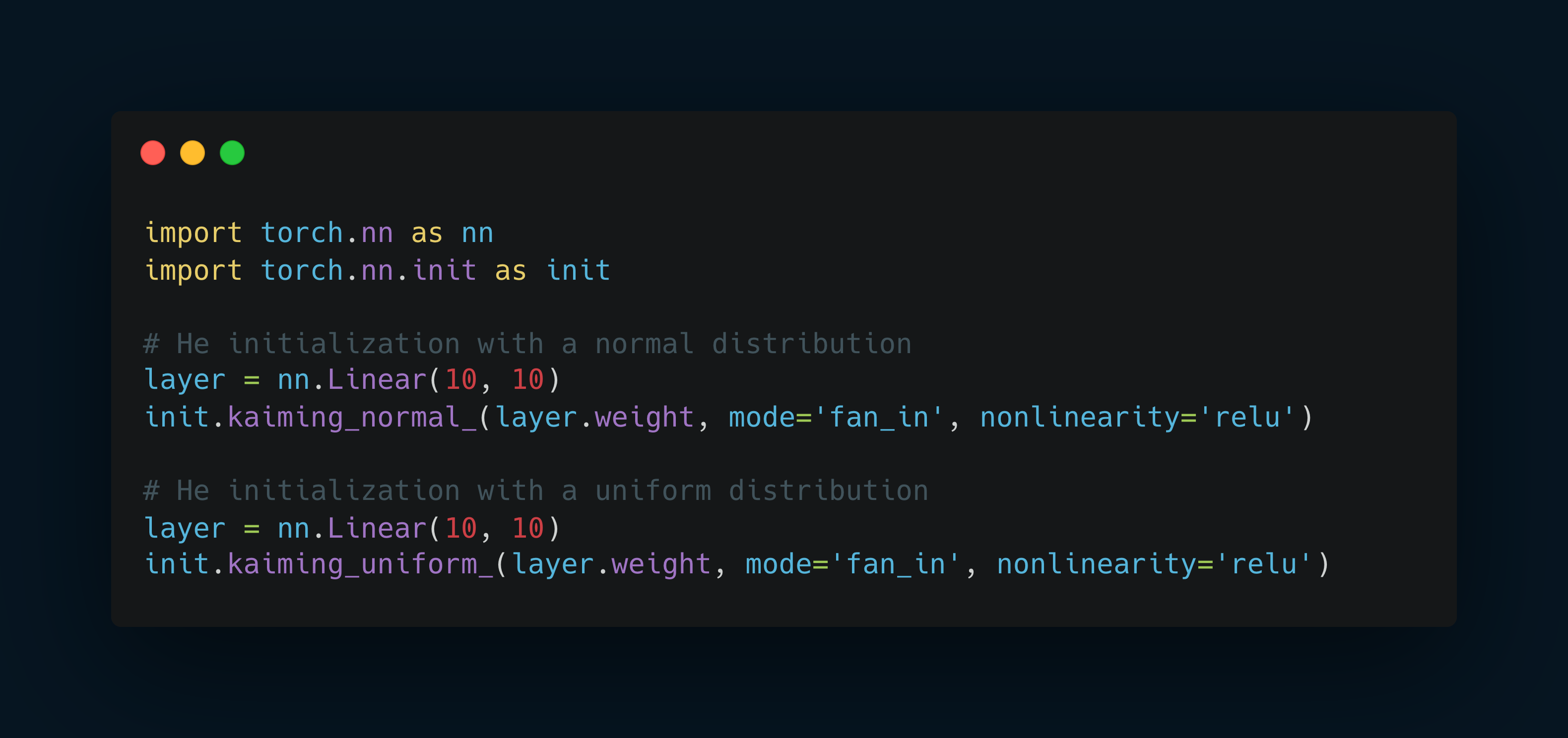
He Initialization
In PyTorch, you can set He (or Kaiming) initialization using either a normal or a uniform distribution.
This is done by applying the initialization to the layer's weights after its creation.
Xavier/Glorot Initialization
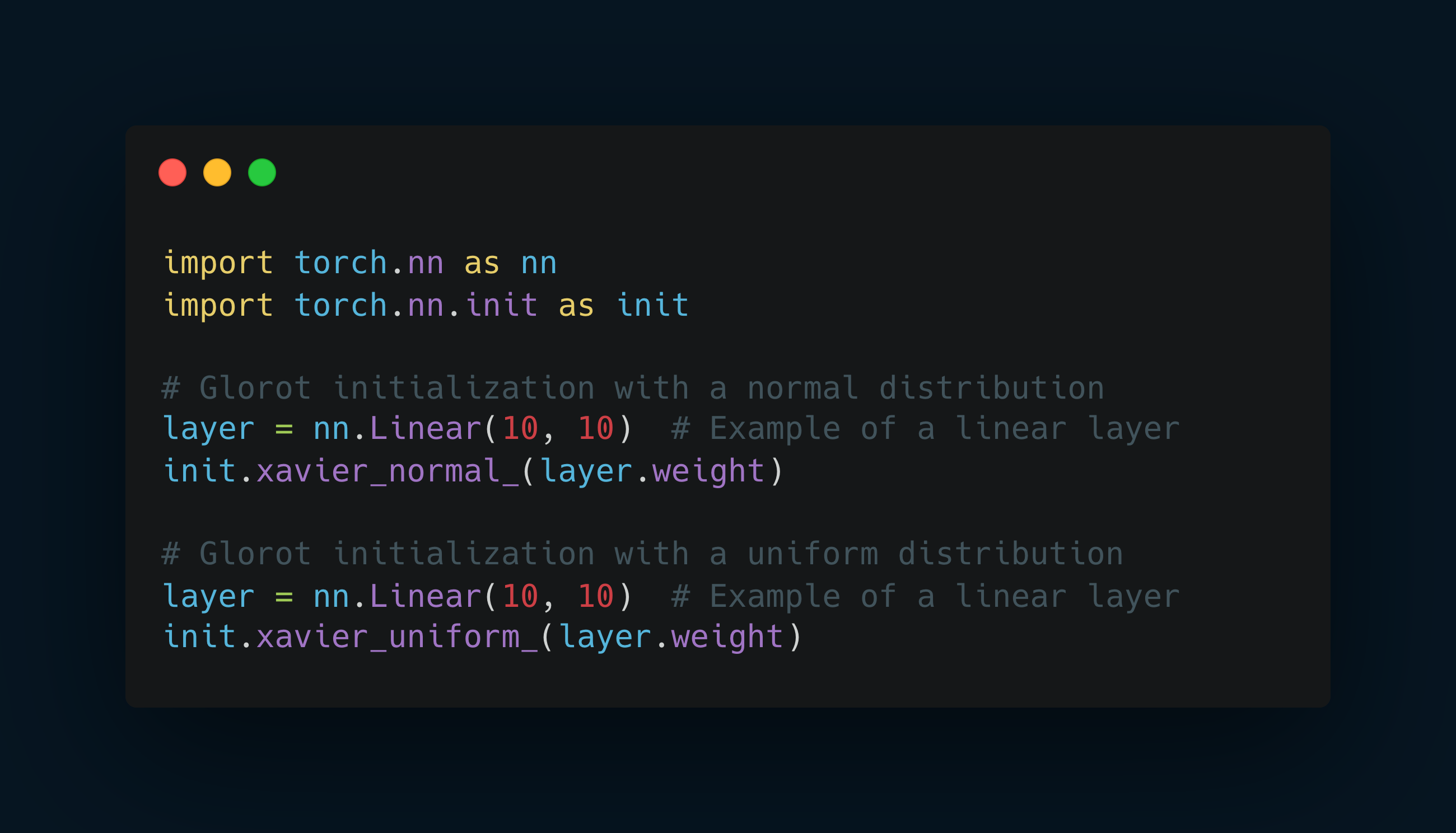
Conclusion
Proper weight initialization is fundamental to preventing vanishing and exploding gradients, ensuring efficient and effective learning.
Different activation functions necessitate specific initialization strategies, such as Xavier/Glorot for Sigmoid/Tanh and He initialization for ReLU.
As we continue to unravel the complexities of deep learning, the importance of foundational steps like weight initialization becomes increasingly clear.
By starting with a balanced and thoughtful approach to weight initialization, we set our neural networks on a path to success, ready to tackle the challenges of learning and adapting.
If you like this article, share it with others ♻️
Would help a lot ❤️
And feel free to follow me for articles more like this.




