
Unveiling the Mysteries of Convolutional Autoencoders for Image Denoising


Ever dreamt of an AI that could master the art of image compression and denoising like a pro?
Enter the world of Convolutional Autoencoders (CAEs), the unsung heroes.
By the way, they are the based of Variational Autoencoder (VAE), used for the Stable Diffusion technique for image generation using AI.
Want to know the secret? Encode images into a latent space, which is then decoded into a new transformed image.
Sound interesting?
Dive into the realm of CAEs. Discover how they're transforming the landscape of image denoising🌟📸🤖
Notes:
This article is based on an original blog post titled Building Autoencoders in Keras by François Chollet.
Original Jupyter Notebook here!
Follow me if you want to read more about my ML/AI journey.
Share with others. Sharing is caring.
Understanding Autoencoders: The Basics
What are Auto-encoders?
Autoencoders, at their core, are about compression and reconstruction.
They're like the wizards of the data world - taking large amounts of information and distilling it into something more manageable, yet still meaningful.
The Dual Components
Encoder:
The encoder is the 'compression guru'.
It transforms the original data into a more compact form, finding the most efficient representation.
Decoder:
The decoder is the 'reconstruction artist'.
It takes the compressed data and rebuilds it back into its original form.
Applications
Anomaly detection: Discarding irregularities in data.
Image denoising: Cleaning up visual data.
Data compression: Reducing data size for efficiency.
Image generation: Support Stable Diffusion using Variational Autoencoder (VAE)
More!
Architecture of Autoencoders
An autoencoder is made up of 3 main components; namely, an encoder, a bottleneck and a decoder.
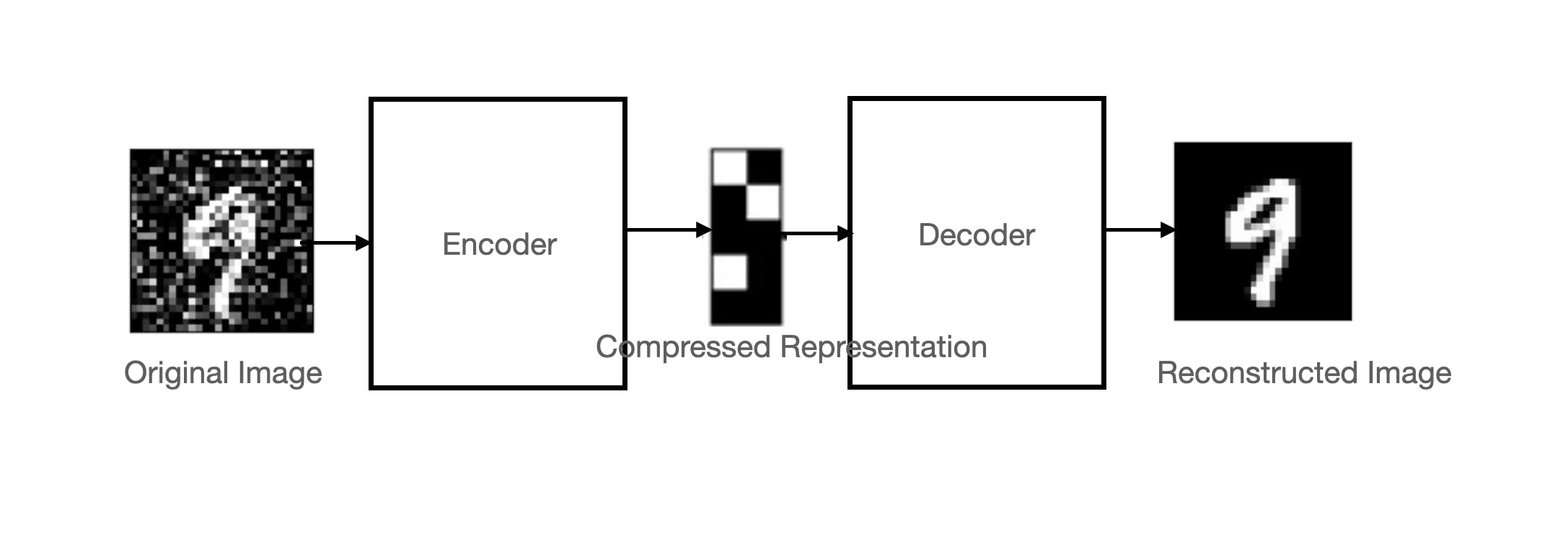
Delving into the Encoder
Conv2D Layers:
These layers are the 'feature artists'.
They use convolution operations to highlight important features in data like textures and edges.
MaxPooling2D Layers:
These are the 'simplifiers'.
They reduce data size while keeping significant features, easing the computational load.
Exploring the Decoder
Conv2D Layers in Decoder:
- Here, these layers work on reconstructing the original data from the compressed form.
Conv2DTranspose Layers:
The 'expanders' of the decoder.
They upscale the data, gradually bringing back the original size and detail.
In essence, the encoder compresses the input using convolution and down-sampling, while the decoder reconstructs it using convolution and up-sampling.
This dance of compression and reconstruction is what makes convolutional autoencoders a cornerstone in image processing tasks.
Implement Autoencoders in Pytorch
Import the dependencies
Add utility functions

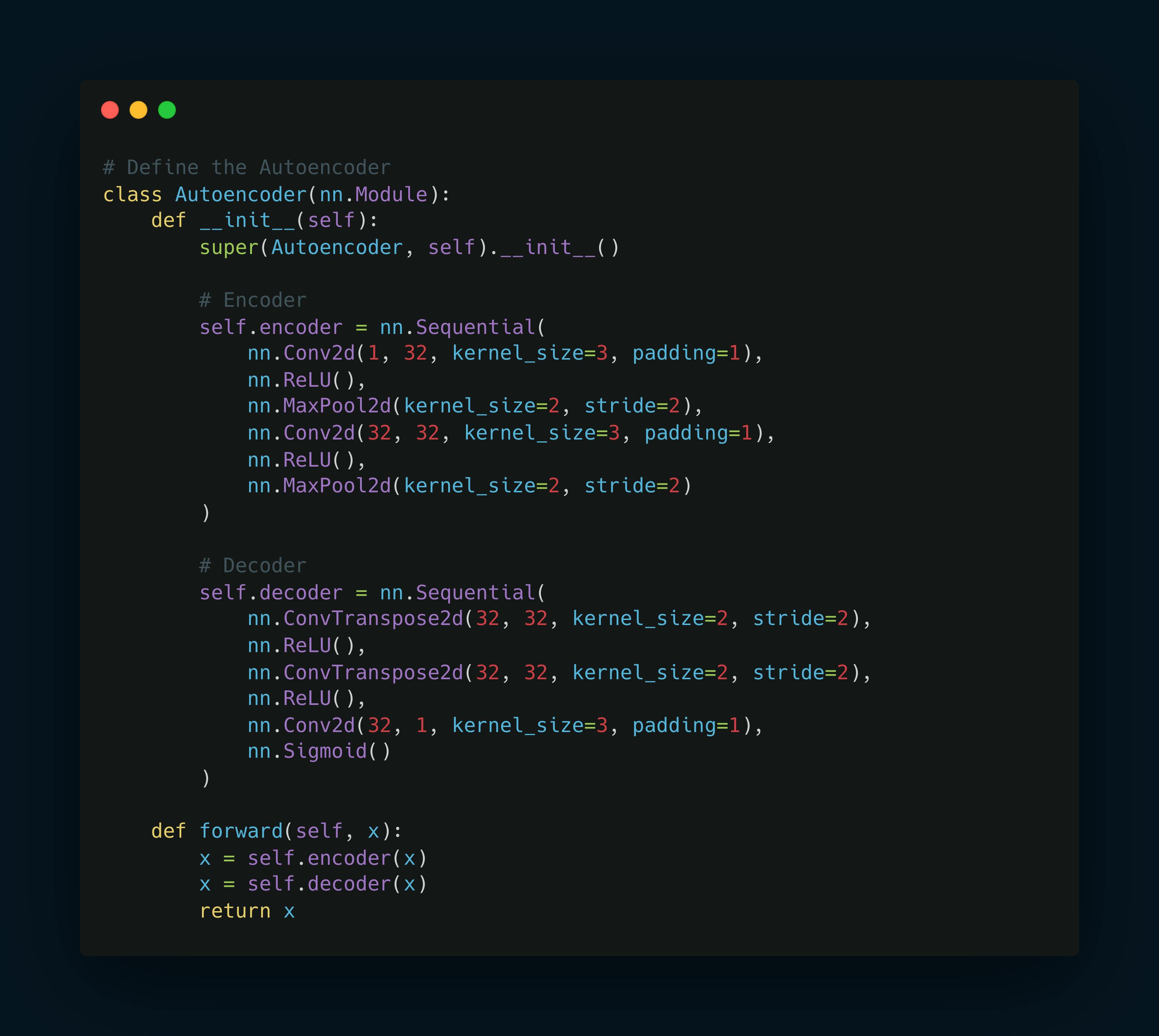
Define the Autoencoder
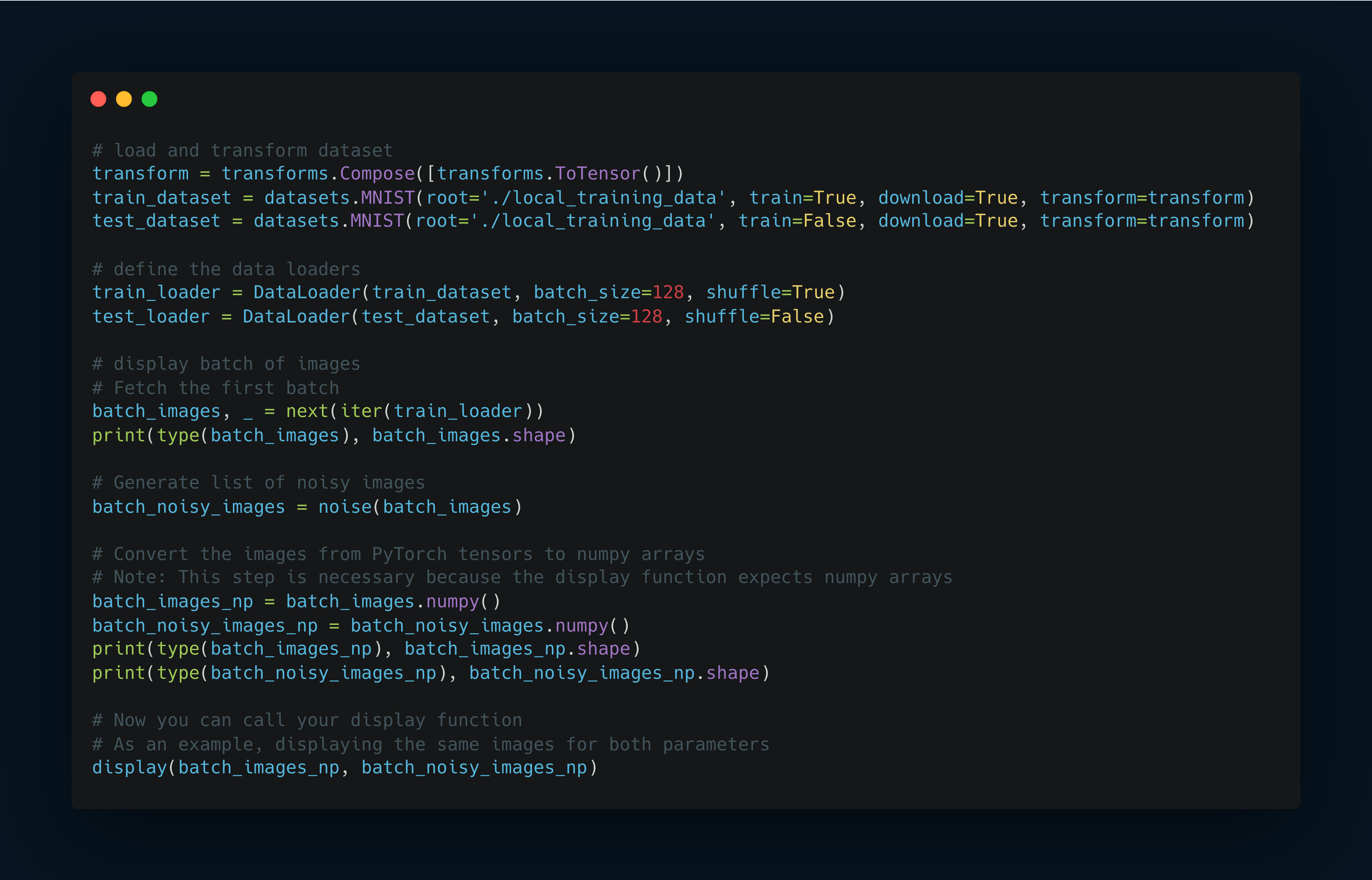
Load and transform the dataset

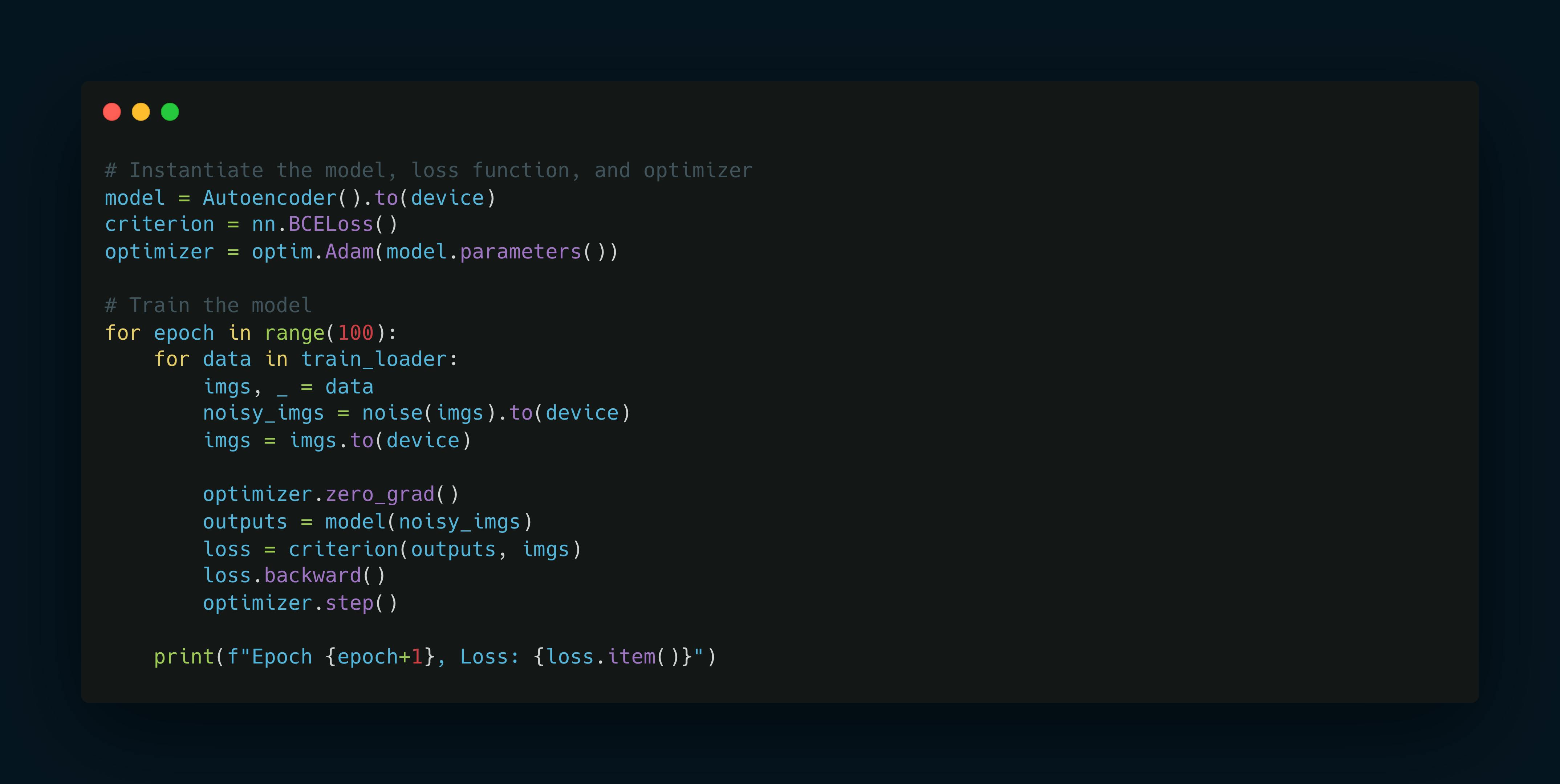
Instantiate and train the model
Test the model


Conclusion
In conclusion, Convolutional Autoencoders (CAEs) represent a remarkable intersection of data compression and neural network technology.
This article has taken you on a journey through the intricate workings of CAEs.
The significance of CAEs extends beyond mere data compression. They are pivotal in numerous practical applications, ranging from anomaly detection in data to image denoising and even complex tasks like dimensionality reduction.
The encoder and decoder's synergistic functions, utilizing Conv2D, MaxPooling2D, and Conv2DTranspose layers, demonstrate the elegant efficiency of these models in handling and interpreting complex data.
Now it's your turn.
Embrace these concepts not only enhances our comprehension of AI systems but also opens up new avenues for innovation and practical application in the digital world.
If you like this article, share it with others ♻️
Would help a lot ❤️
And feel free to follow me for articles more like this.