


In the ever-evolving realm of neural networks, ensuring that models generalize well to new, unseen data is a cardinal pillar.
One of the key techniques that have emerged as a savior in enhancing model generalization is Batch Normalization.
This powerful technique has revolutionized the way neural networks are trained, enabling the construction of deeper and more robust models.
Let’s dive into the essence of Batch Normalization and unravel its magic!
What is normalization?
Before we delve into Batch Normalization, it’s crucial to understand the concept of normalization.
Normalization is a technique that aims to make the data samples more homogeneous, ensuring that the model encounters data that is on a similar scale.
This is instrumental in helping the model learn effectively and generalize well to new data.
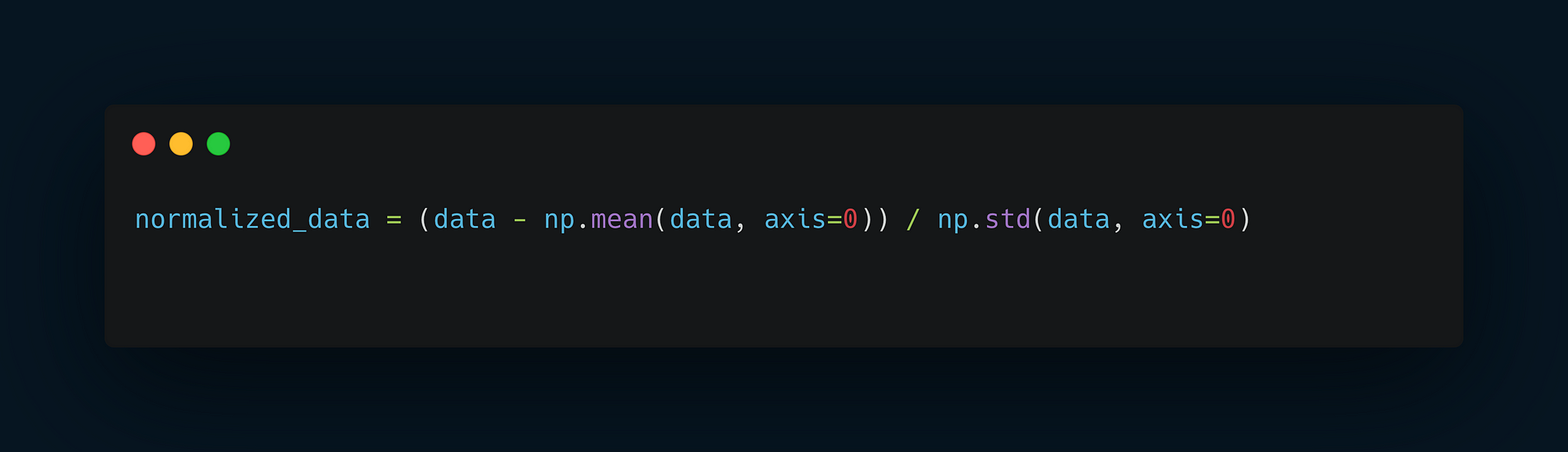
A common practice in normalization is to center the data around 0 and give it a unit standard deviation.
This is achieved by subtracting the mean and dividing by the standard deviation of the data.
Normalization of training data.
Normalization is not a one-time affair. It should be diligently applied after every transformation within the network to maintain consistency and stability in the data distribution.
Batch Normalization: How does it work?
Batch Normalization operates as a layer within the network. It maintains an exponential moving average of the batch-wise mean and variance of the data encountered during training.
This is not just a layer; it’s a catalyst that enhances the training process, ensuring that the network learns the features more effectively.
One of the remarkable impacts of Batch Normalization is its ability to bolster gradient propagation, acting much like residual connections.
This facilitation allows for the creation of deeper networks, pushing the boundaries of what models can learn and achieve.
Integration in Networks
Batch Normalization has been embraced and integrated liberally in advanced convolutional network architectures, such as ResNet50, Inception V3, and Xception, which are readily available in frameworks like Keras.
It is commonly employed after convolutional or densely connected layers, ensuring that the data is normalized post-transformation.
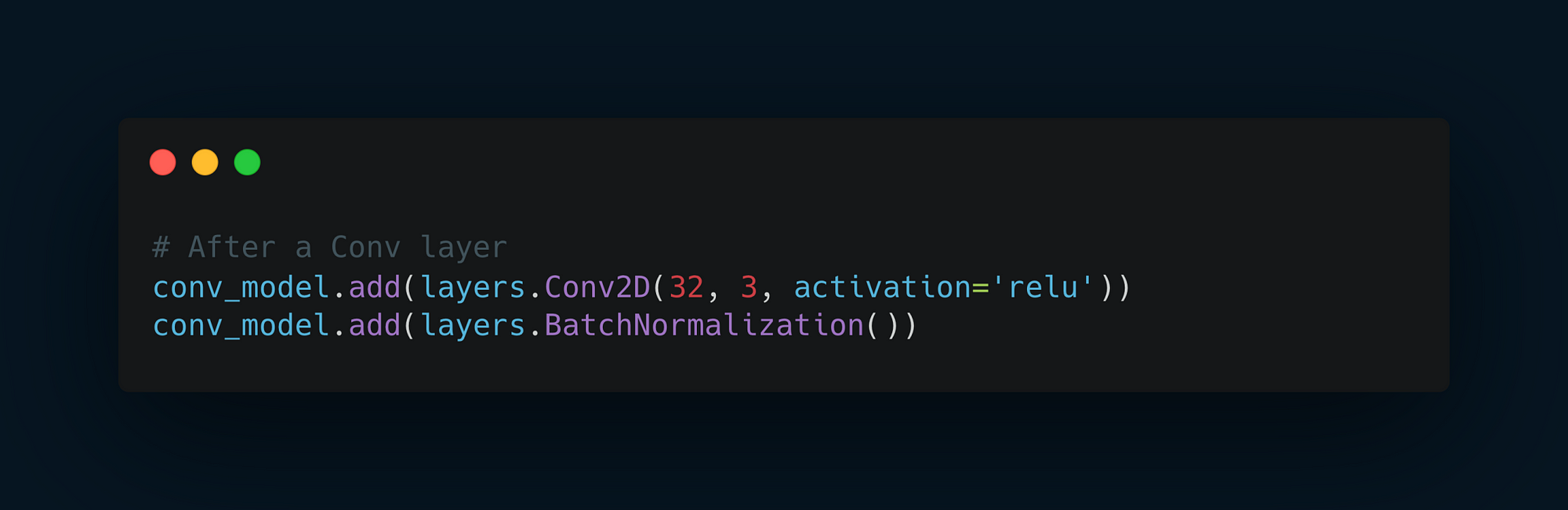
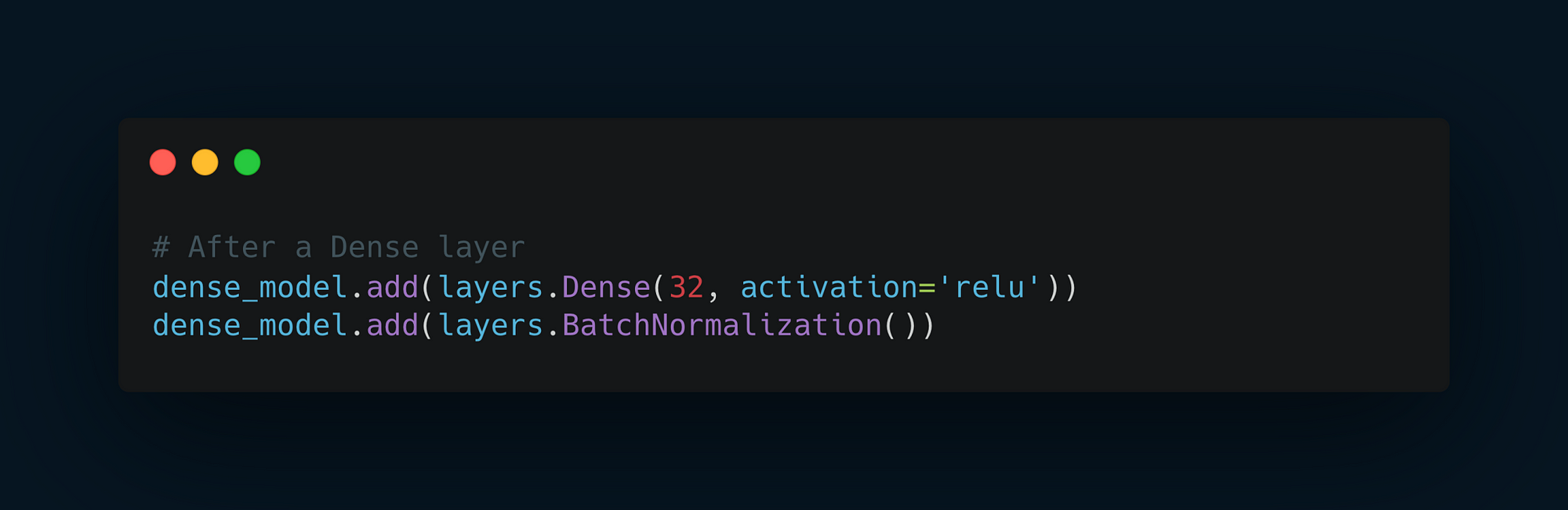
Customization and Flexibility
Batch Normalization comes with a degree of flexibility, allowing customization through the axis argument.
This argument specifies the feature axis to be normalized, providing control over the normalization process.
Advantages and Disadvantages of Using Batch Normalization
Advantages
1. Accelerated Training
Batch Normalization facilitates faster model training. By maintaining a stable distribution of activations, it mitigates the issues caused by fluctuating distribution, also known as internal covariate shift.
This leads to an acceleration in the convergence of the training process, allowing models to reach optimal performance more swiftly.
2. Higher Learning Rates
Traditionally, choosing a higher learning rate might lead to divergence during training. Batch Normalization alleviates this issue, allowing the use of higher learning rates, further contributing to faster convergence and improved model performance.
3. Reduced Dependency on Initialization
Batch Normalization makes models less sensitive to the initial weights.
This reduces the dependency on choosing a specific initialization strategy, making the training process more robust and less susceptible to the choice of initial weights.
4. Acts as a Regularizer
Interestingly, Batch Normalization exhibits a slight regularization effect.
This means it can reduce the need for other regularization techniques such as Dropout, simplifying the model architecture and the training process.
Disadvantages
1. Computational Overhead
Batch Normalization introduces additional computations during the training process. This can lead to increased training times, especially when dealing with complex models and large datasets.
It’s a trade-off that needs careful consideration based on the specific use case and resources available.
2. Reduced Model Interpretability
The introduction of Batch Normalization layers adds complexity to the model, making it more challenging to interpret. Understanding the impact and contribution of each layer becomes less straightforward, which might be a consideration in scenarios where model interpretability is crucial.
3. Batch Size Sensitivity
Batch Normalization is sensitive to batch size. Smaller batch sizes might lead to inaccurate estimates of mean and variance, affecting model performance. This sensitivity necessitates careful selection of batch size to ensure that the benefits of Batch Normalization are effectively harnessed.
Conclusion: Embracing the Magic
Batch Normalization is not just a technique; it’s a great way to train neural networks.
It acts as a guardian, ensuring that the data remains consistent and conducive for the model to learn effectively.
Its ability to enhance gradient propagation unlocks the doors to deeper and more powerful networks, opening up a new era in neural network training.
You can try Batch Normalization in your models and see the results! 🚀
If you like this article, share it with others ♻️