Revolutionizing Retrieval: The Mastering Hypothetical Document Embeddings (HyDE)

Senior AI Engineer | Building & Telling Stories about AI/ML Systems | Software Engineer
In the dynamic universe of Retrieval-Augmented Generation (RAG) systems, a perplexing question often surfaces: How does one construct an effective RAG system when relevant labels for queries are absent?
Don't worry! I've been researching about this topic recently.
What I found can save you lots of hours of investigation.
A groundbreaking innovation has emerged on the horizon, christened as Hypothetical Document Embeddings (HyDE), paired with the ingenious implementation of LangChain.
This novel approach has redefined the paradigms of retrieval, introducing strategies that help handle the complexities of relevance and retrieval.
What is HyDE?
HyDE employs a Language Learning Model (LLM), such as ChatGPT to generate a hypothetical document in response to a query, instead of using the query and the underlying computed vector to directly search in the vector database.
It takes a step further by employing an unsupervised, contrastively learned encoder.
This encoder transforms the generated hypothetical document into an embedding vector to fetch similar documents in a vector database.
We're not finding embedding similarity for questions/query. We are doing answer-to-answer embedding similarity.
It showcases robust performance, standing toe-to-toe with fine-tuned retrievers across a spectrum of tasks like web search, QA, and fact verification.
Algorithm
- step01: feed the query to the LLM. Instruct it to "write a document that answers the question". It contains factual errors but is like a relevant document.
This generated document, while interspersed with elements of factual flexibility, maintains a foundational alignment with relevant document structures.
- step02: use an unsupervised encoder to encode this document into an embedding vector.
This phase is characterized by a strategic filtration process, wherein extraneous details are meticulously pruned to accentuate the core relevance attributes.
- step03: use this vector to search against the vector db. Returns the most similar documents.
Code
Init HypotheticalDocumentEmbedder. Print out the prompt. Compute the embedding.
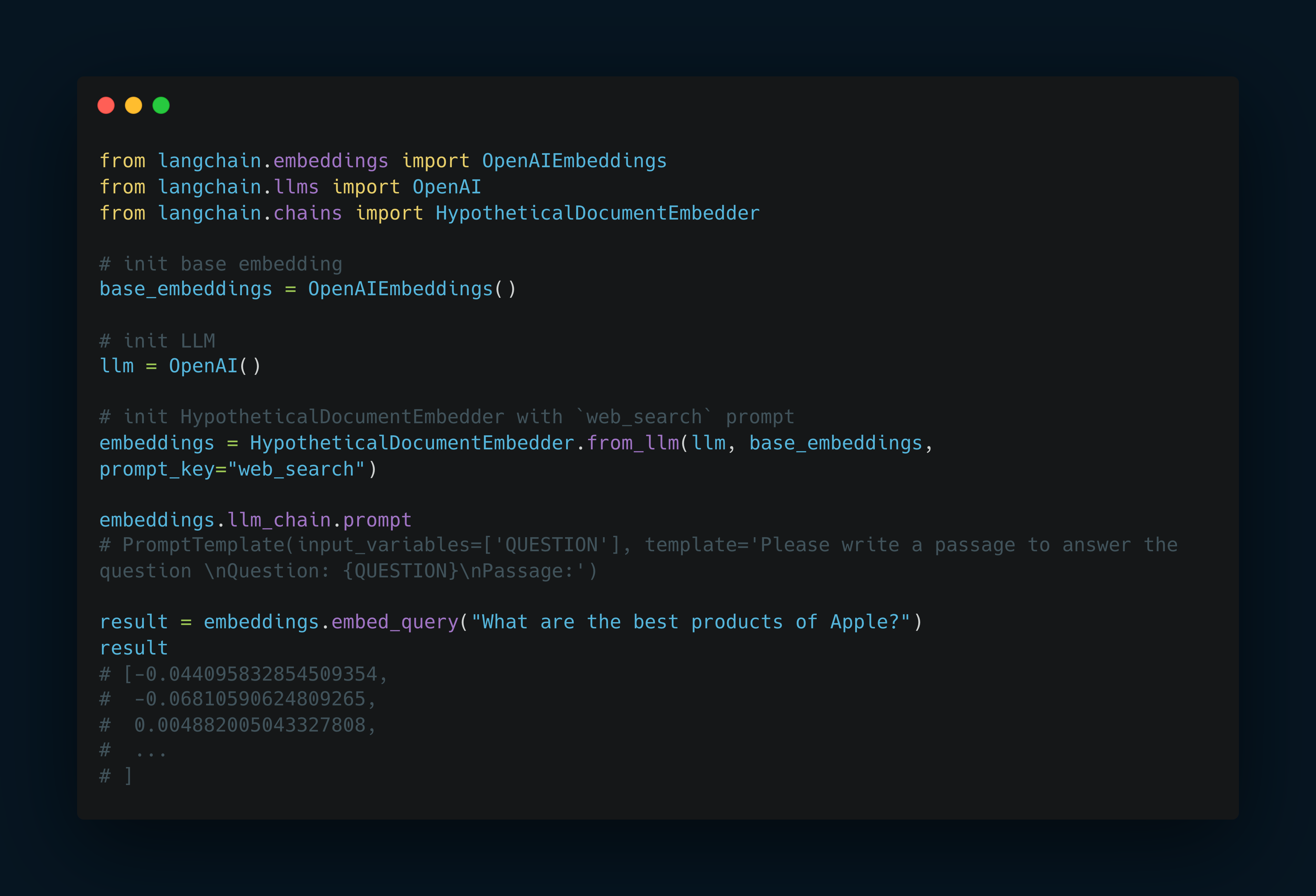
Init HypotheticalDocumentEmbedder
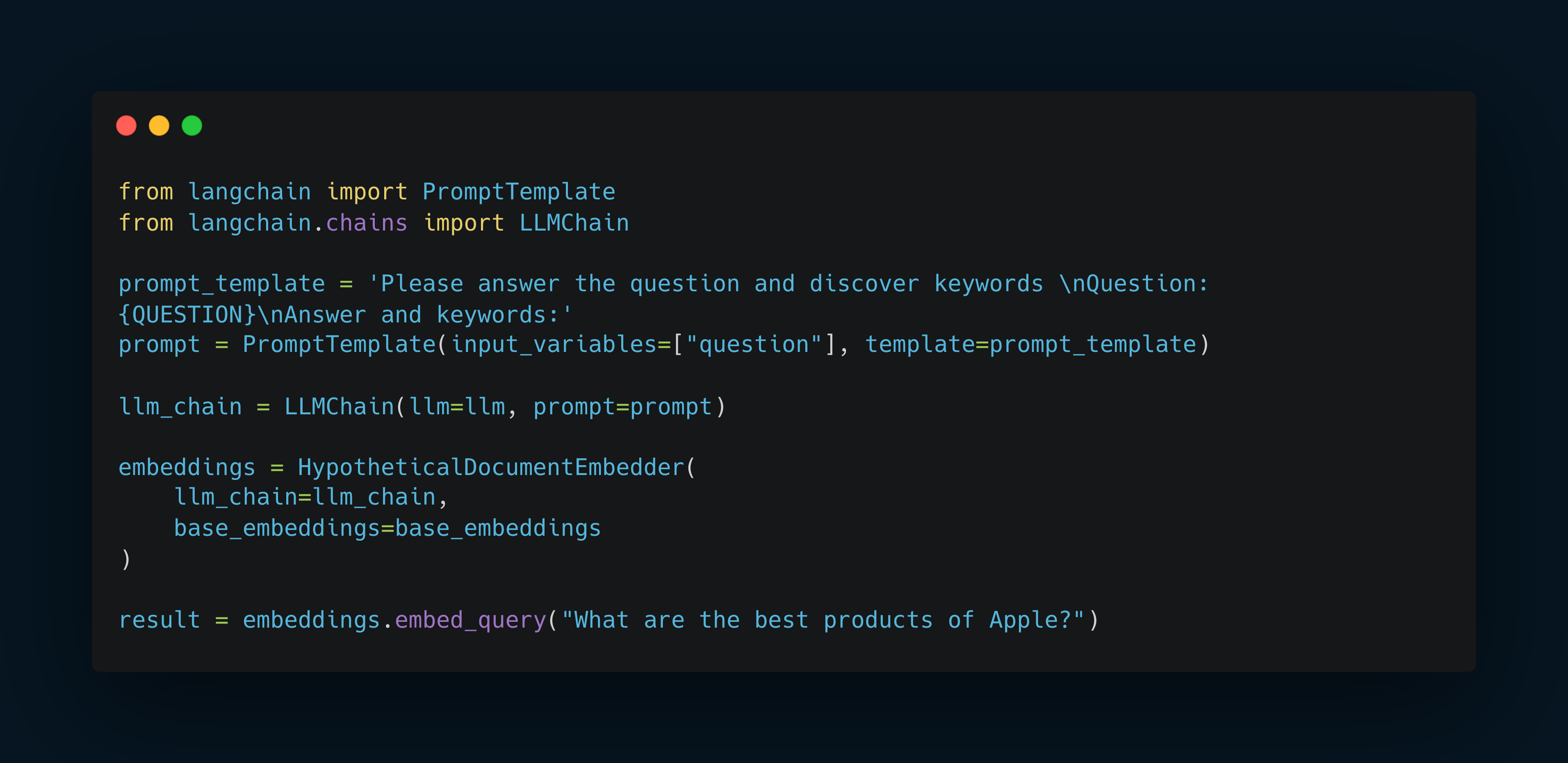
Use HypotheticalDocumentEmbedder as other embedding class in your code.
Useful Links
You can read the paper here: https://arxiv.org/pdf/2212.10496.pdf
Conclusion
HyDE emerges as a vanguard in the technological evolution of Retrieval-Augmented Generation (RAG) systems.
Its architectural sophistication is characterized by the strategic integration of hypothetical documents, encoder mechanisms, and embedding vectors.
This leads to a transformative era marked by enhanced precision, relevance, and retrieval efficacy. 🚀
If you like this article, share it with others ♻️
Would help a lot ❤️




