Random Forests in Machine Learning

Senior AI Engineer | Building & Telling Stories about AI/ML Systems | Software Engineer
Imagine having a team of experts, each bringing their unique perspective to solve a complex problem.
Now, what if you could combine their insights to make a decision that's more accurate than any single expert's opinion?
This is the essence of a Random Forest, a concept in machine learning that harnesses the power of multiple decision trees to make more accurate predictions and analyses.
Random Forests stands as one of the most effective and widely used algorithms.
Their simplicity, coupled with their powerful ability to make accurate predictions, makes them a favorite in the machine-learning realm.
Let's dive into the world of Random Forests, exploring how they work, their applications, and why they are so crucial in predictive modeling.
What is a Random Forest?
A Random Forest is an ensemble learning technique.
Ensemble learning combines the predictions from multiple machine learning algorithms to make more accurate predictions than any individual model.
A Random Forest, specifically, is an ensemble of Decision Trees, typically trained with the bagging method to improve the predictive accuracy and control over-fitting.
The Mechanics Behind Random Forest
Ensemble of Decision Trees: In a Random Forest, numerous decision trees operate as an ensemble. Each tree is trained on a random subset of the data, which makes the trees diverse and the overall predictions more balanced and less biased.
Bagging Method: The training process involves the bagging method, where multiple subsets of the dataset are created with random sampling, and each tree in the forest is trained independently on these subsets.
Aggregation of Predictions: When making predictions, each tree in the forest predicts an outcome for the input data. The Random Forest algorithm then aggregates these predictions. For classification tasks, it adopts a majority voting system, while for regression, it averages the outputs.
Handling Overfitting: One of the critical strengths of Random Forests is their ability to control overfitting, which is a common problem with individual decision trees.
Why Use Random Forests?
The appeal of Random Forests in various applications lies in their versatility and effectiveness. Here's why they are so popular:
High Accuracy: By aggregating the predictions of multiple trees, Random Forests often yield more accurate results than individual trees.
Robustness: They are less prone to overfitting and are robust to noise and outliers in the data.
Feature Importance: Random Forests can identify the most influential features in the training data, providing valuable insights.
Flexibility: They can be used for both classification and regression tasks, making them highly versatile.
Ease of Use: Implementing a Random Forest model is straightforward, especially with libraries like Scikit-Learn offering efficient and optimized solutions.
Random Forests in Scikit-Learn
In Python's Scikit-Learn library, using Random Forests is made exceptionally convenient.
The RandomForestClassifier and RandomForestRegressor classes simplify the implementation, offering an optimized and user-friendly interface.
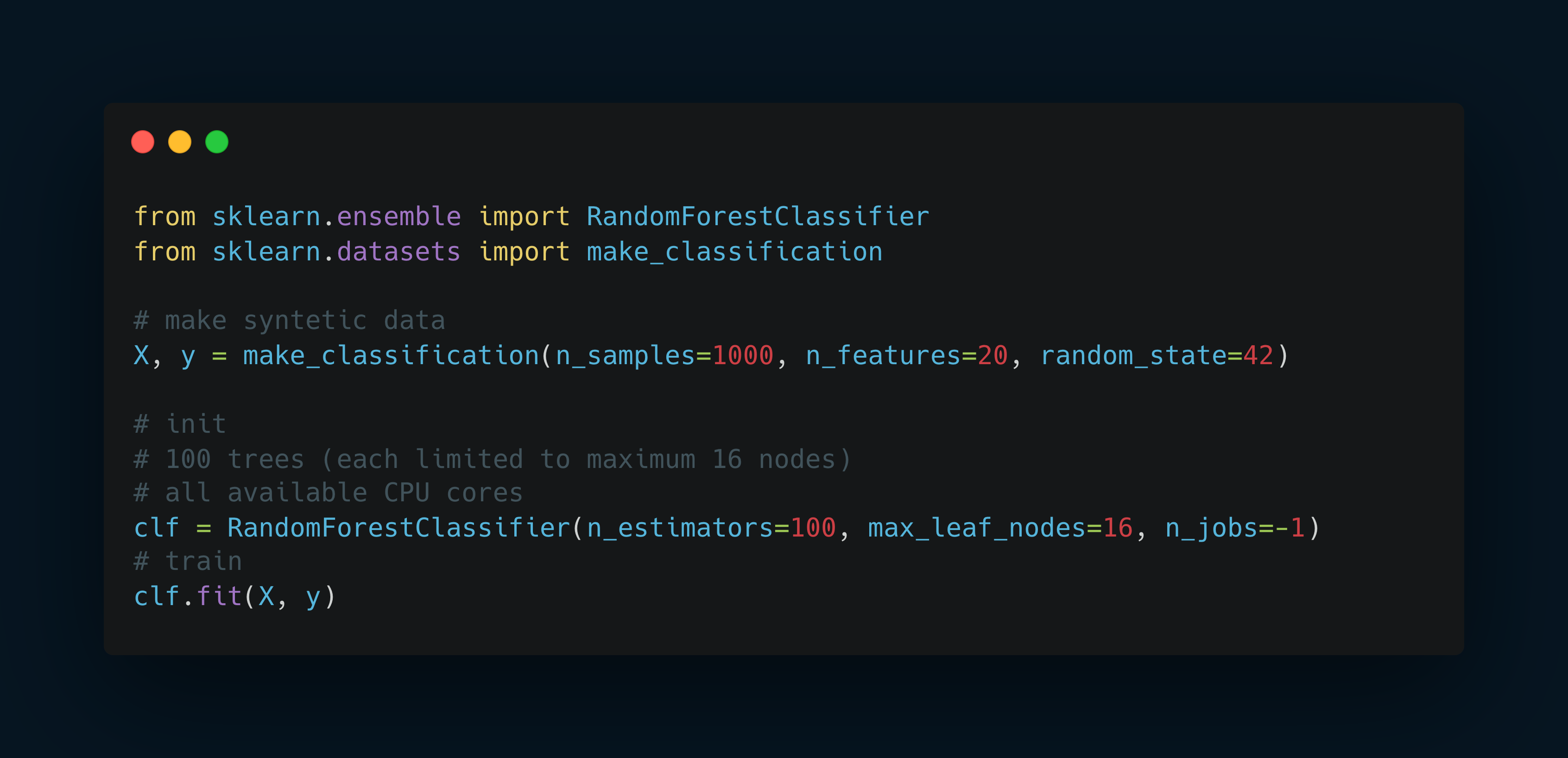
Training a Random Forest Model
Here's a basic example of how to train a Random Forest Classifier in Scikit-Learn:
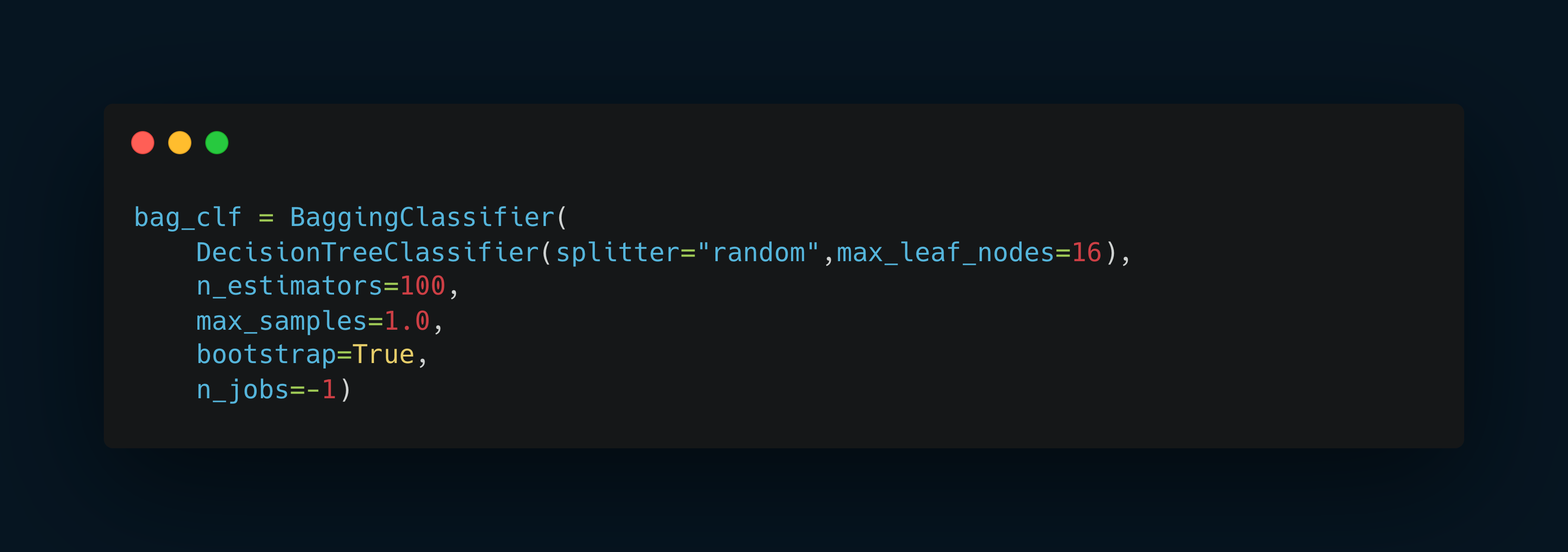
The following BaggingClassifier is roughly equivalent to the previous RandomForestClassifier.
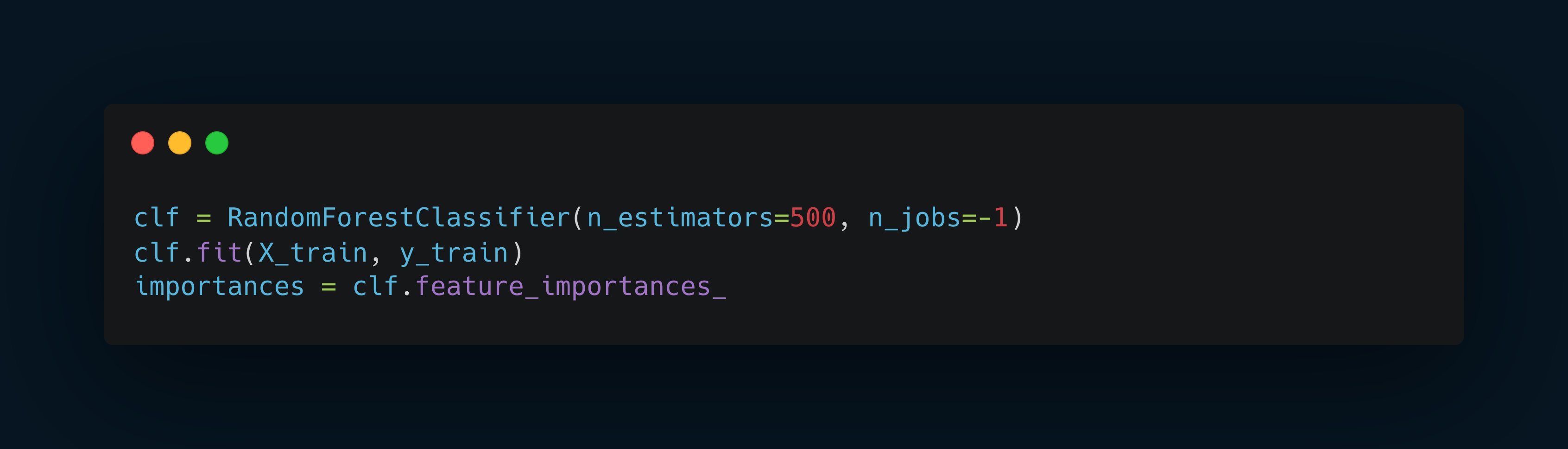
Feature Importance in Random Forests
A significant advantage of Random Forests is their ability to evaluate the importance of different features in making predictions.
Scikit-Learn's RandomForestClassifier and RandomForestRegressor automatically compute this and store it in the feature_importances_ attribute.
Limitations and Considerations
While Random Forests are powerful, they are not without limitations:
Model Interpretability: They are not as interpretable as individual decision trees.
Performance: They require more computational resources and time to train than simpler models.
Large Data Handling: They can struggle with very large datasets.
Conclusion
Random Forests stand as a testament to the power of combining simplicity and effectiveness in machine learning.
Their ability to harness the strengths of multiple decision trees to make more accurate and robust predictions makes them a valuable tool in Machine Learning.




