Mini-Batch Gradient Descent: Optimizing Machine Learning

Senior AI Engineer | Building & Telling Stories about AI/ML Systems | Software Engineer
In this article, you'll discover the magic behind mini-batch gradient descent.
It cleverly breaks down the data into manageable, bite-sized pieces, making the learning process not just efficient but a tad playful.
So, buckle up and prepare for a journey through the inner workings of Mini-Batch Gradient Descent and how it's implemented using Scikit-Learn.
What is Gradient Descent?
Imagine a hiker seeking the lowest point in a valley—their journey is akin to gradient descent, a cornerstone optimization algorithm in machine learning.
In this context, gradient descent is the hiker, navigating through a landscape of data to find the minimal point of error or cost.
This technique is vital for training algorithms, especially in machine learning models like neural networks and logistic regression.
By iteratively adjusting parameters, gradient descent ensures that the model's predictions on training data are as accurate as possible, constantly moving towards minimal error.
Importance in Machine Learning
In the world of machine learning, gradient descent is akin to a fine-tuning instrument.
It's essential for learning from data, refining model parameters, and essentially 'teaching' the algorithm to make better predictions.
The accuracy and efficiency of a model depend heavily on how well the gradient descent is applied, making it a critical component in the machine learning toolkit.
Types of Gradient Descent
Gradient descent manifests in three primary forms:
Batch
Stochastic
Mini-Batch.
Each variant has its unique approach to processing training data and updating model parameters, but they all share the common goal of minimizing the error gradient.
Batch Gradient Descent
Traditional batch gradient descent processes the entire dataset in one go. This method, while straightforward, can be slow and computationally demanding, especially with large datasets.
Stochastic Gradient Descent
Stochastic Gradient Descent (SGD) takes a different route by updating the model after evaluating each data point.
It's faster but can lead to variability in the learning process due to the frequent updates.
Mini-Batch Gradient Descent
Mini-Batch Gradient Descent strikes a balance between Batch and Stochastic methods.
It divides the data into smaller batches, processing each batch separately.
Basically, instead of computing the gradients based on the full training set (as in Batch GD) or based on just one instance (as in Stochastic GD), Mini-batch GD computes the gradients on small random sets of instances called mini-batches.
The main advantage of Mini-batch GD over Stochastic GD is that you can get a performance boost from hardware optimization of matrix operations.
This method offers a compromise between speed and stability, making it a popular choice in deep learning applications.
Detailed Analysis of Mini-Batch Gradient Descent
Let’s say you have a data set with a million or more training points.
What’s a reasonable way to implement supervised learning?
One approach, of course, is to only use a subset of the rows.
Mini-Batch Gradient Descent is like a skilled juggler, managing the trade-off between computational efficiency and the fidelity of the error gradient.
It processes data in smaller, manageable chunks, allowing quicker and more frequent updates than batch gradient descent, yet more stable and efficient than the stochastic approach.
How Mini-Batch Gradient Descent Works
Imagine dividing a large dataset into several mini-batches.
Each batch is processed, contributing to the overall learning of the model.
This division allows for more frequent updates, speeding up the learning process while ensuring more stability compared to SGD.
Configuring Mini-Batch Gradient Descent
Configuring the size of each mini-batch is a crucial aspect.
It's a balancing act between computational resources and learning efficiency.
Common batch sizes include 32, 64, or 128 data points, which are often chosen based on the hardware capabilities, like GPU or CPU memory.
Mathematical Approach to Mini-Batch Gradient Descent
Mathematically, Mini-Batch Gradient Descent involves calculating the error for each batch and updating the model parameters accordingly.
The algorithm iteratively adjusts these parameters to minimize the overall error across all batches.
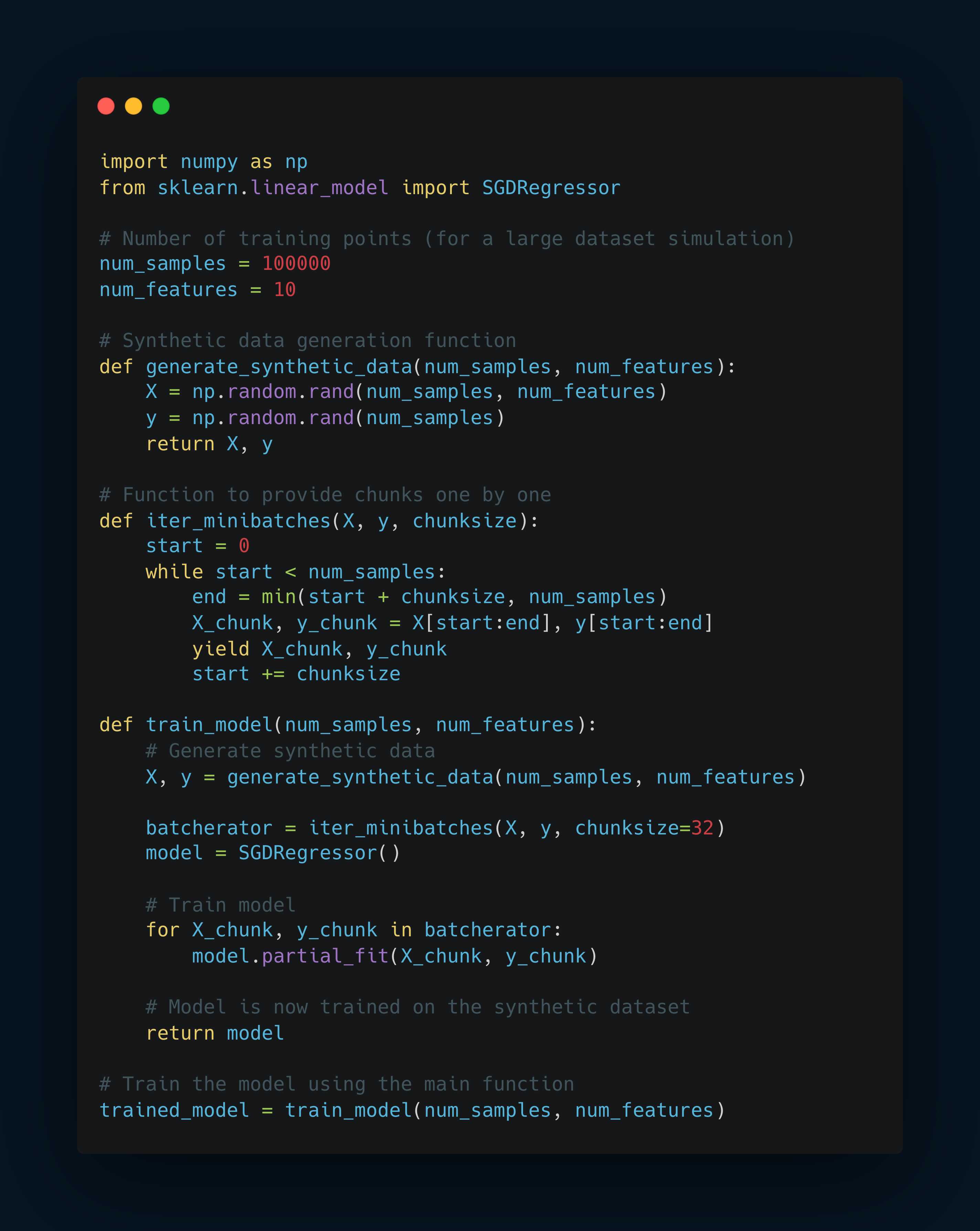
Mini-Batch Gradient Descent in Scikit-Learn
The SGDRegressor and SGDClassifier classes in Scikit-Learn's sklearn.linear_model module are designed for large-scale learning, especially when dealing with large datasets or online learning scenarios.
The key feature that enables this is the partial_fit method, which supports mini-batch learning.
partial_fit method
Unlike traditional estimators in Scikit-Learn that require the entire dataset to be provided at once for training (via the fit() method), the partial_fit() method allows for incremental learning.
This means that the model can be trained on smaller portions or "batches" of the dataset sequentially.
Conclusion
In the realm of Scikit-Learn, Mini-Batch Gradient Descent stands as a testament to efficient and scalable machine learning.
Embracing the power of the partial_fit method, this approach adeptly handles large datasets by breaking them into mini-batches, offering a practical solution to memory constraints and computational challenges.
In this article, we see how Mini-Batch Gradient Descent in Scikit-Learn is not just a technique, but a strategic ally in navigating the vast oceans of data in the modern world.




