Measuring Similarity Between Two Input Entities using Embeddings: A Deep Dive

Senior AI Engineer | Building & Telling Stories about AI/ML Systems | Software Engineer
Have you ever wondered how to measure the similarity or interaction between two entities using Machine Learning?
I got you! I also had that question before.
Recently, I've been researching embeddings and dot product as way to measure similarity.
I'm going to share the ideas here, so you can save time on the initial research. Just adapt them to your use case.
This concept is a cornerstone in various domains such as recommendation systems, natural language processing, and many others.
The challenge lies in accurately quantifying the degree of similarity or interaction between entities in a way that is computationally efficient and meaningful.
In this article, we will show how to tackle this problem using embedding layers and dot products in a neural network model.
I'm going to illustrate the ideas by a code example using TensorFlow and Keras.
The Challenge
The key problem is defining and quantifying the 'similarity' or 'interaction' between two entities.
Entities could be users and items in a recommendation system, words in natural language processing, or any other pair of elements that interact in some way.
Traditional methods might rely on predefined rules or heuristic methods to measure similarity, but these approaches often lack flexibility and adaptability.
The Solution: Embeddings and Dot Products
A modern, effective solution is to use neural network embeddings.
Embeddings are dense vector representations that can capture the essence of an entity in continuous vector space.
The code example provided illustrates a model that utilizes embedding layers to convert input entity IDs into such dense vectors.
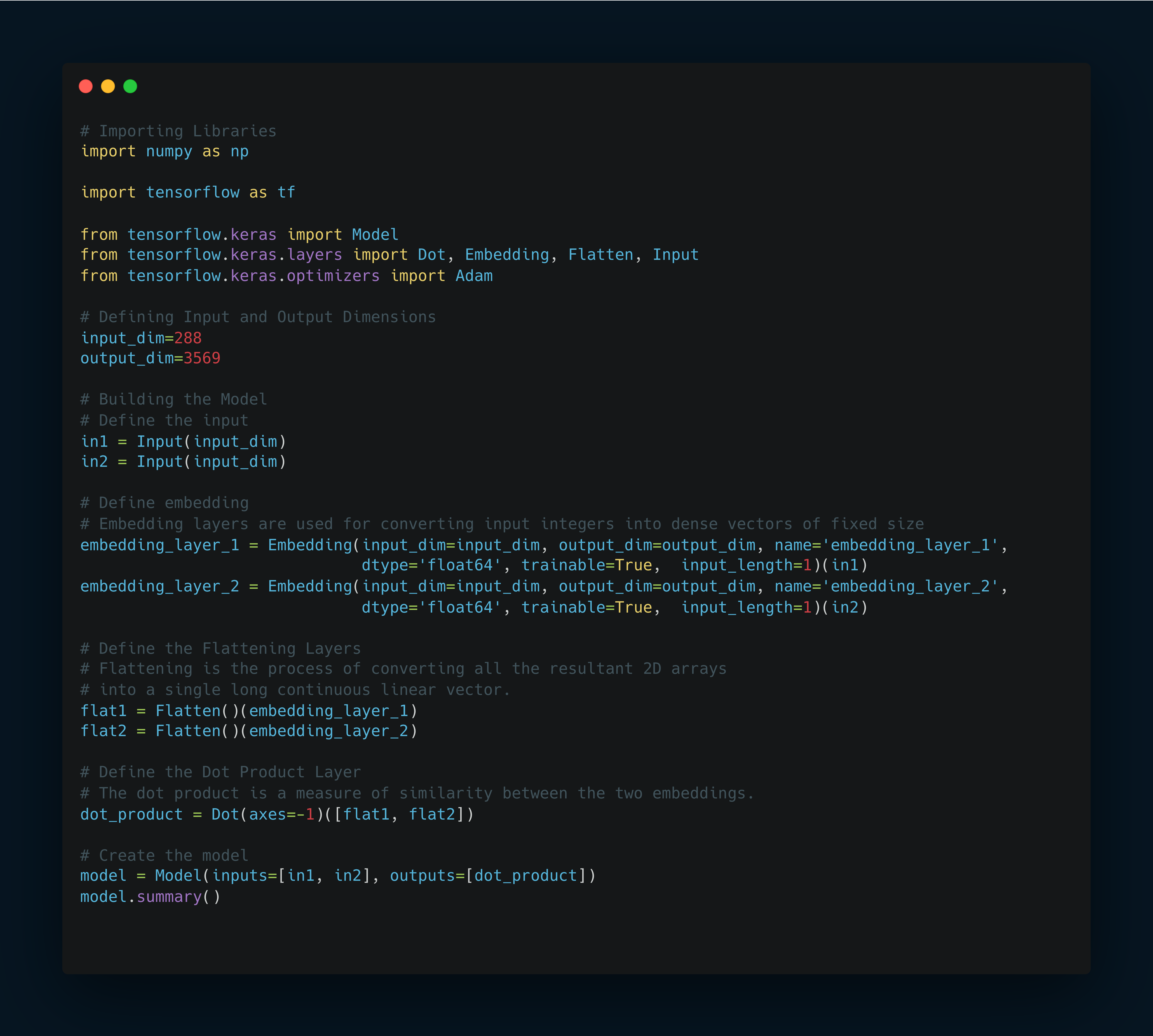
This model takes two inputs, passes them through embedding layers, flattens the embeddings, and then calculates the dot product of the two flattened embeddings.
Embedding Layers
The model begins by defining two embedding layers, each responsible for converting an entity ID into a dense vector. These vectors are learned during the training process, allowing each entity to be represented in a way that captures its interactions or similarities with other entities.
Flattening and Dot Product
The embeddings are then flattened, and a dot product is calculated. The dot product acts as a measure of similarity, providing a single value that quantifies the interaction between the two entities.
Compile the model
After defining the architecture of the model, the next step is to compile it. Compiling the model means configuring it for training, which involves specifying the optimizer, loss function, and evaluation metric.
After defining the architecture of the model, the next step is to compile it. Compiling the model means configuring it for training, which involves specifying the optimizer, loss function, and evaluation metric.

After compiling, the model is ready to be trained using the fit method with the training data.
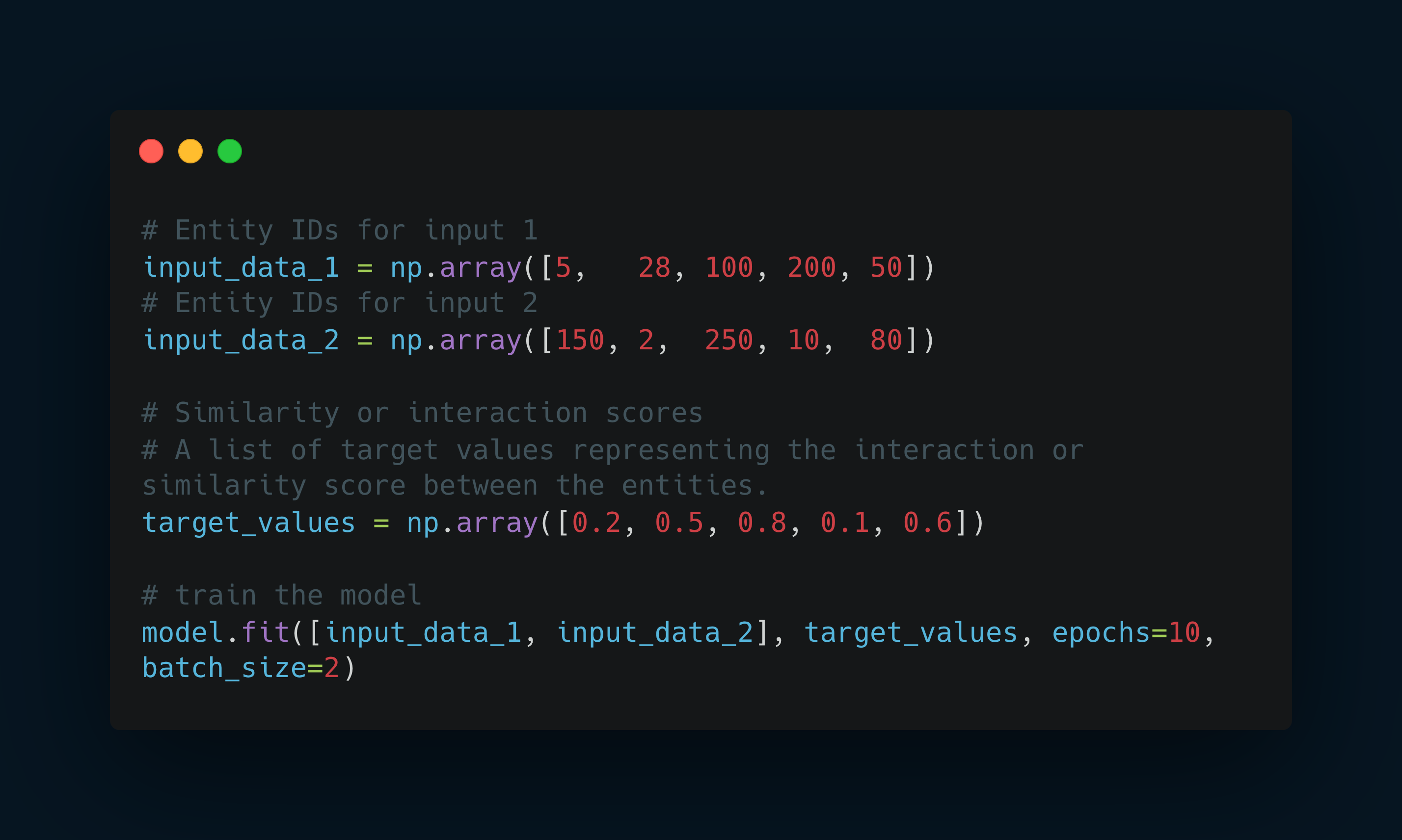
Training the Model
Training involves optimizing the model parameters to minimize a cost function, which could be a measure of the difference between the model’s predictions and actual similarity scores in the training data.
The model learns the best embeddings and relationships to accurately predict the interactions or similarities in the training data.
We can encode the similarity using the rule:
Negative Score: A negative score might indicate dissimilarity or a weaker relationship between the entities in a pair.
Positive Score: A positive score suggests some level of similarity or interaction between the entities, with higher positive values indicating stronger relationships.
The magnitude of the Score: The magnitude (absolute value) of the score can be interpreted as the strength of the similarity or interaction. A score closer to zero indicates weaker similarity or interaction.
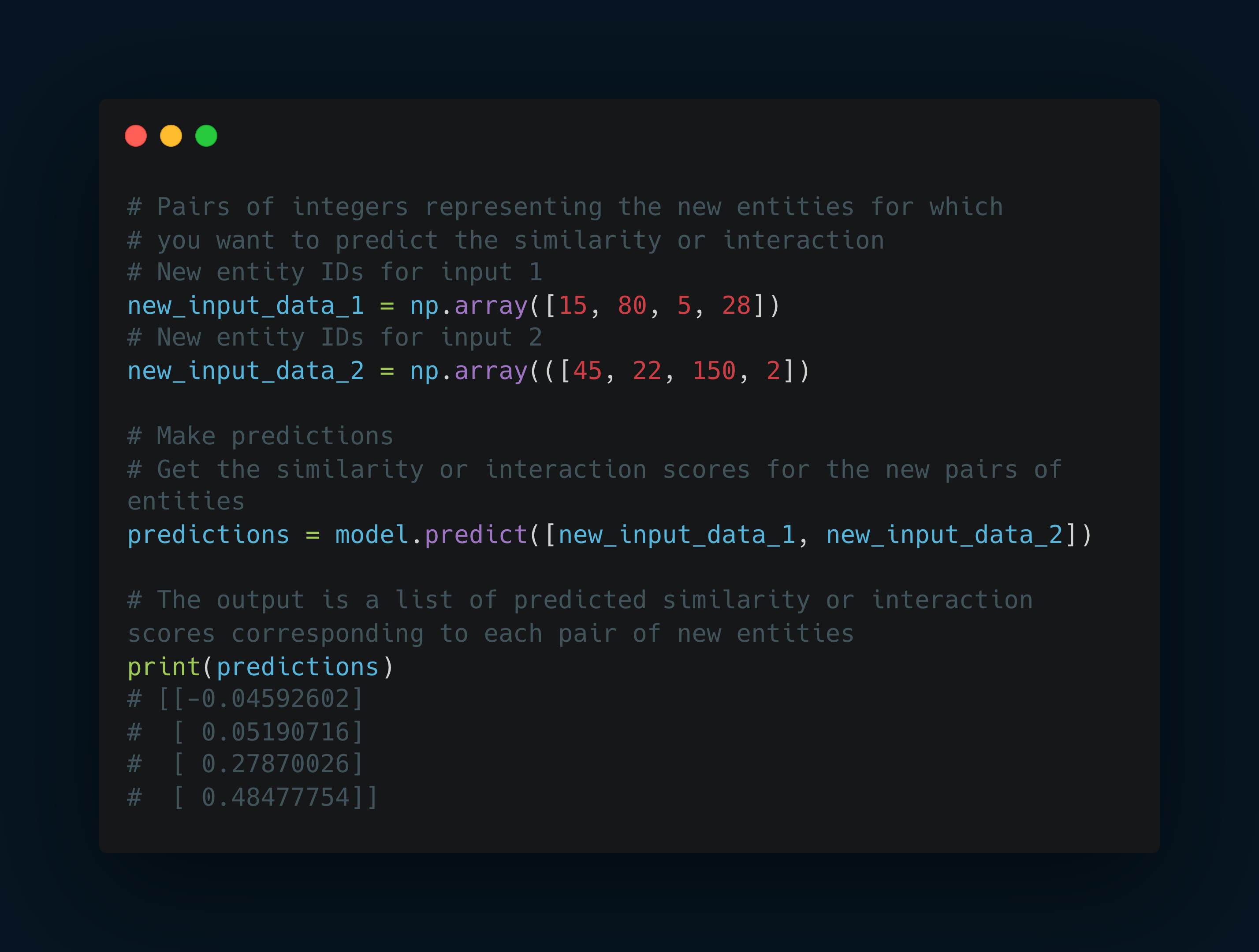
Making Predictions
Once trained, the model can predict the similarity or interaction between new pairs of entities.
This is done by passing the entity IDs through the model, which outputs a prediction score based on the learned embeddings and relationships.
Conclusion
The method illustrated in the code offers a powerful and flexible way to measure the similarity or interaction between entities.
By leveraging embeddings and neural network architectures, it allows for the learning of complex relationships and interactions in a data-driven manner, providing a robust solution to the challenge of quantifying similarity or interaction in various domains and applications.
Now that you have all the concepts and tools to measure the similarity between entities using machine learning, embeddings and dot product, then you can apply them to your use case.




