
Harnessing the Power of Transfer Learning in Deep Learning: A Comprehensive Guide


Recently, I was involved in project for classifying images.
The Challenge?
We were working with a limited dataset — just around 10,000 images.
But our ambitions didn't match our resources; we aimed to push our model's performance to an accuracy of over 97%.
Have you ever grappled with such a daunting task in your real-world ML projects?
Enter transfer learning and fine-tuning to the game.
In this comprehensive guide, we dig into how transfer learning and fine-tuning can turn limited data into a treasure trove of learning opportunities.
Remember to follow me if you want to read more about my ML/AI journey.
Introduction to Transfer Learning
Understanding the Core Concept
Transfer learning is a strategy where knowledge gained while solving one problem is applied to a different but related problem.
In deep learning, this involves using a model trained on a large dataset and adapting it to a more specific task.
Why Use Transfer Learning?
Efficiency
Transfer learning dramatically reduces the need for large datasets and extensive computing resources, a common hurdle in traditional ML projects.
This approach is particularly advantageous when dealing with complex tasks like image or speech recognition.
Training a model from scratch demands significant computational power and a vast amount of data.
Effectiveness
It offers a significant head start in the learning process.
When you use a model that has already been trained on a large, diverse dataset, it has already learned a substantial amount of useful patterns and features.
This pre-acquired knowledge can be effectively transferred to a new, but related task.
As a result, the model doesn’t start from zero; it starts from a point of informed understanding.
Versatility
Transfer learning is incredibly versatile and can be applied across various domains and tasks.
Whether it's adjusting a model trained on general photographs to specialize in medical imaging, or adapting a language model to understand industry-specific jargon, the applications are vast and varied.
This flexibility makes it an invaluable tool in the arsenal of data scientists and machine learning practitioners.
Cost-Effectiveness
In terms of time and money, transfer learning is a cost-effective solution.
Training a model from scratch is resource-intensive, requiring substantial computational time and power.
Using pre-trained models cuts down on these resources, leading to significant cost savings, especially in terms of processing power and time-to-deployment.
Reducing Overfitting
When working with a small dataset, there's always a risk that a model trained from scratch might overfit.
Transfer learning helps mitigate this risk.
The pre-trained layers provide a more generalized learning base, making the model less prone to memorizing the training data and more adept at generalizing from the patterns it has learned.
The Transfer Learning Workflow in Deep Learning
The Basic Steps
Start with a Pre-Trained Model: Take layers from a model trained on a large dataset.
Freeze the Layers: Prevent the pre-trained layers from updating during training.
Add New Layers: Include trainable layers to adapt the model to the new task, for example, a dense layer for classification
Train on New Data: Adjust the new layers to the specific requirements of your task.
Optional: Fine-Tuning
After training the new layers, unfreeze the entire model.
Retrain it on the new data with a very low learning rate.
This step further adapts the pre-trained features to the new task.
Code Example
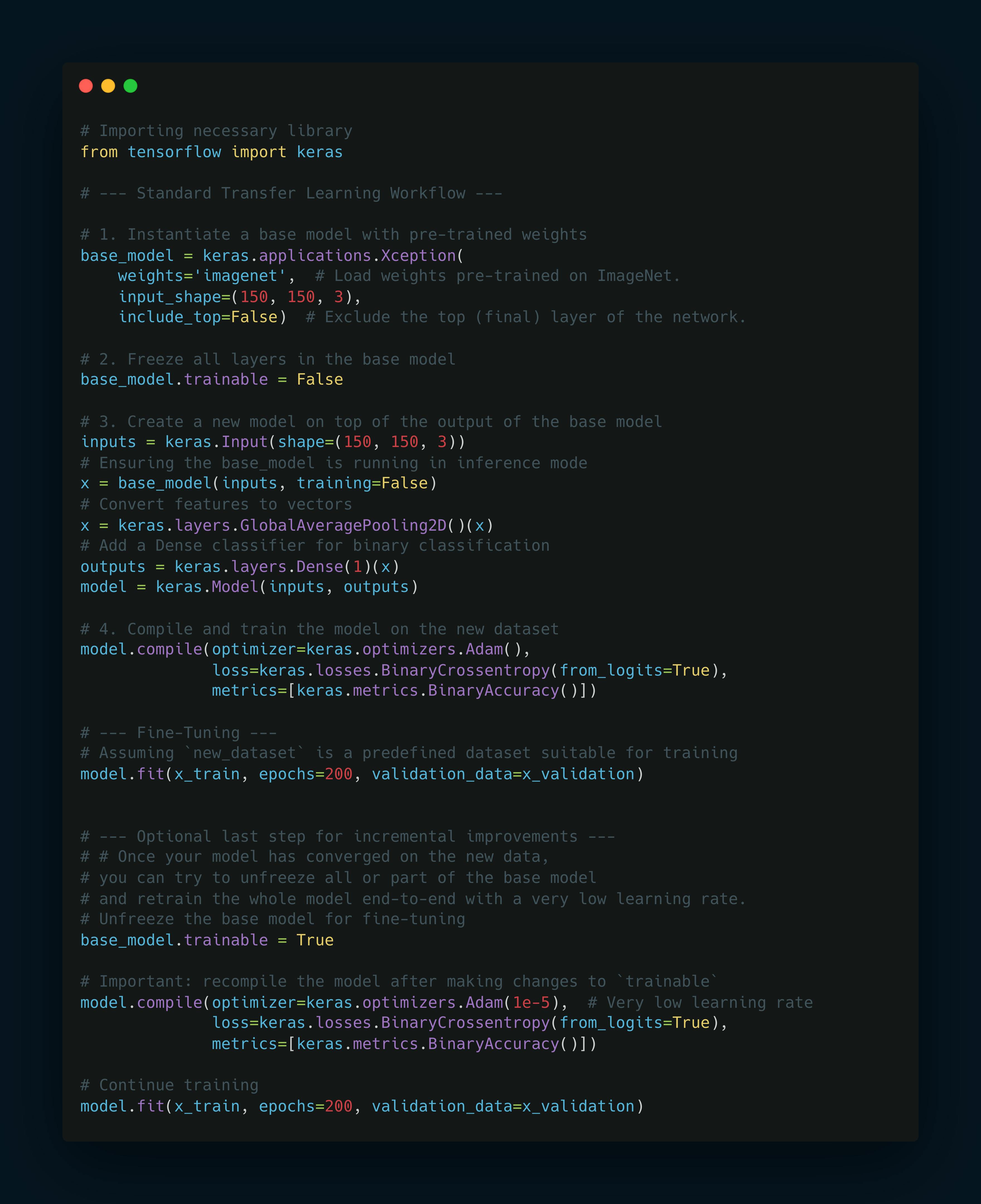
Key Points in the Python Example
Base Model Instantiation:
keras.applications.Xceptionis used to create a base model with weights pre-trained on ImageNet. The top classifier layer is not included (include_top=False).Freezing the Base Model:
base_model.trainable = Falseensures the weights in the Xception model do not change during the initial training phase.Creating the New Model: A new input layer is defined, followed by the base model and new layers like
GlobalAveragePooling2Dand a dense output layer for binary classification.Initial Training: The new model is compiled and trained on the new dataset.
Fine-Tuning: After initial training, the base model is unfrozen (
base_model.trainable = True), and the entire model is recompiled and retrained at a very low learning rate. This fine-tuning step can lead to incremental improvements by slightly adjusting the pre-trained weights based on the new data.
Considerations and Trade-offs
Standard Workflow: Offers flexibility and is typically used when the new task is significantly different from the task the base model was originally trained on.
Lightweight Workflow: More efficient but less flexible. It's ideal when the new task is closely related to the original task of the base model. However, it's not suitable for scenarios requiring dynamic input data modifications, like data augmentation.
Fine-Tuning: An optional but often beneficial step to tailor the pre-trained model more closely to the specific requirements of the new task. However, it requires careful handling to avoid overfitting.
Conclusion
In summary, transfer learning in deep learning is a strategic approach to leverage pre-existing knowledge in models.
It makes it easier and faster to develop models for new, related tasks.
The choice of workflow depends on the specific requirements and constraints of the task at hand.
If you like this article, share it with others ♻️
Would help a lot ❤️
And feel free to follow me for articles more like this.