Dimensionality Reduction in Machine Learning
Senior AI Engineer | Building & Telling Stories about AI/ML Systems | Software Engineer
Have you ever faced the daunting challenge of understanding data with countless features?
Welcome to the world of 'Dimensionality Reduction', a crucial concept in Machine Learning that transforms complexity into simplicity.
Let's go together on a journey to demystify this key technique.
The Curse of Dimensionality: A Real Challenge in Data Science
Imagine navigating a space filled with millions of dimensions.
This is the 'curse of dimensionality', a common problem in machine learning.
High-dimensional datasets often result in sparsity, where most training instances are isolated from each other.
This isolation poses significant challenges for predictions and increases the risk of overfitting.
Reducing the number of dimensions down to two or maybe three makes it possible to plot the data on a graph, and often gain some important insights by visually detecting patterns, such as clusters.
Apart from speeding up training, dimensionality reduction is also extremely useful for data visualization.
Tackling the Curse: Effective Approaches for Dimensionality Reduction
One might think increasing the size of the training set could counteract this curse.
However, the number of required training instances grows exponentially with each added dimension, making this solution impractical.
To combat these challenges in practice, two main strategies are employed: projection and manifold learning.
Projection: Simplifying the Complex
In the real world, not all dimensions contribute equally.
Many features are either constant or highly correlated.
As a result, training instances often reside within a lower-dimensional subspace.
Projection techniques exploit this fact to reduce dimensions while retaining critical information.
Manifold Learning: Understanding the Underlying Structure
This approach is based on the manifold hypothesis, suggesting that most high-dimensional datasets are close to a lower-dimensional manifold.
Manifold Learning algorithms strive to uncover this hidden structure, providing a more meaningful representation of the data.
Principal Component Analysis (PCA)
PCA stands for Principal Component Analysis, a cornerstone algorithm in dimensionality reduction.
It identifies the axes that maximize the variance in the data, providing a transformed dataset with reduced dimensions.
PCA example.
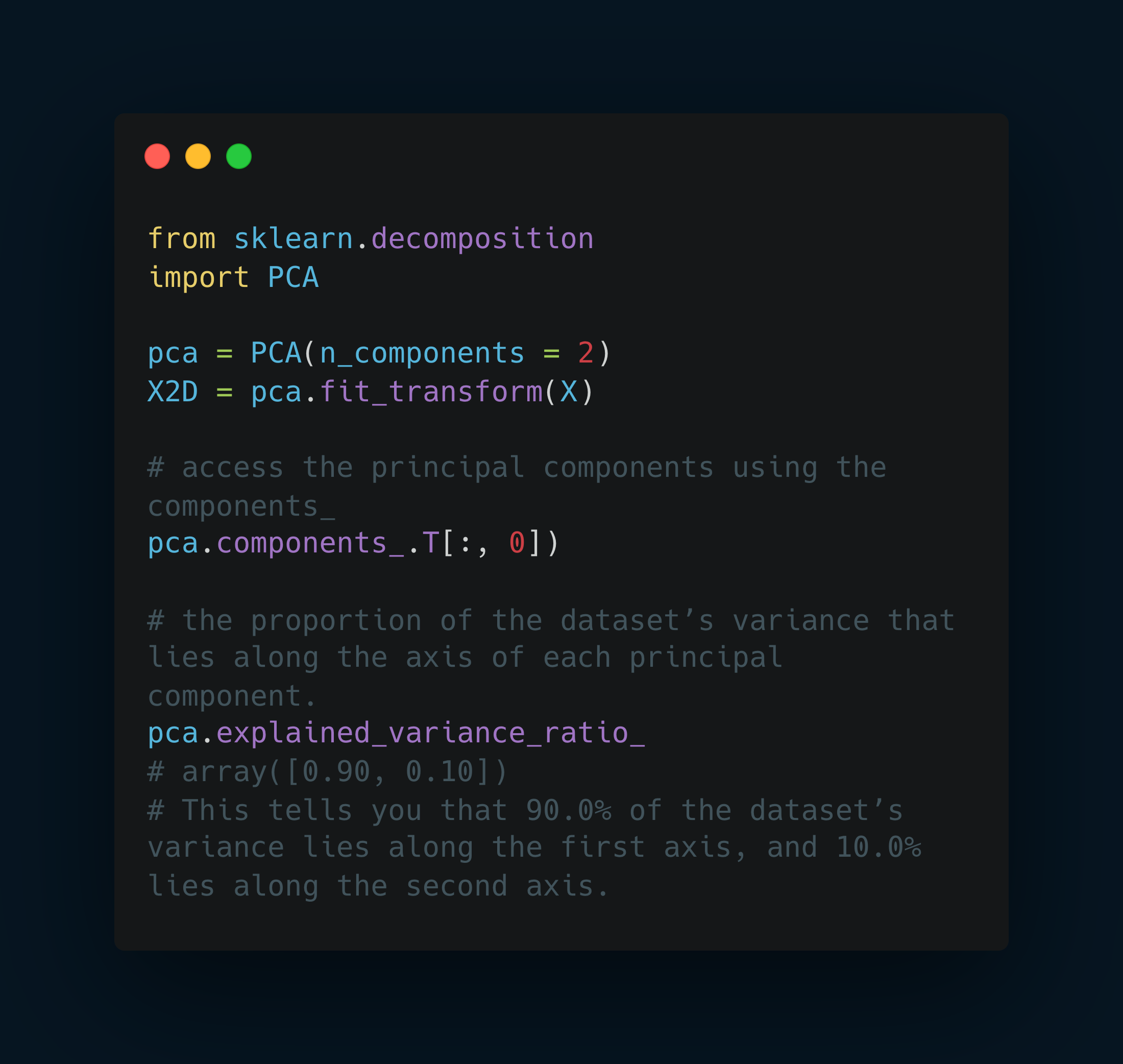
Finding the Right Number of Dimensions.
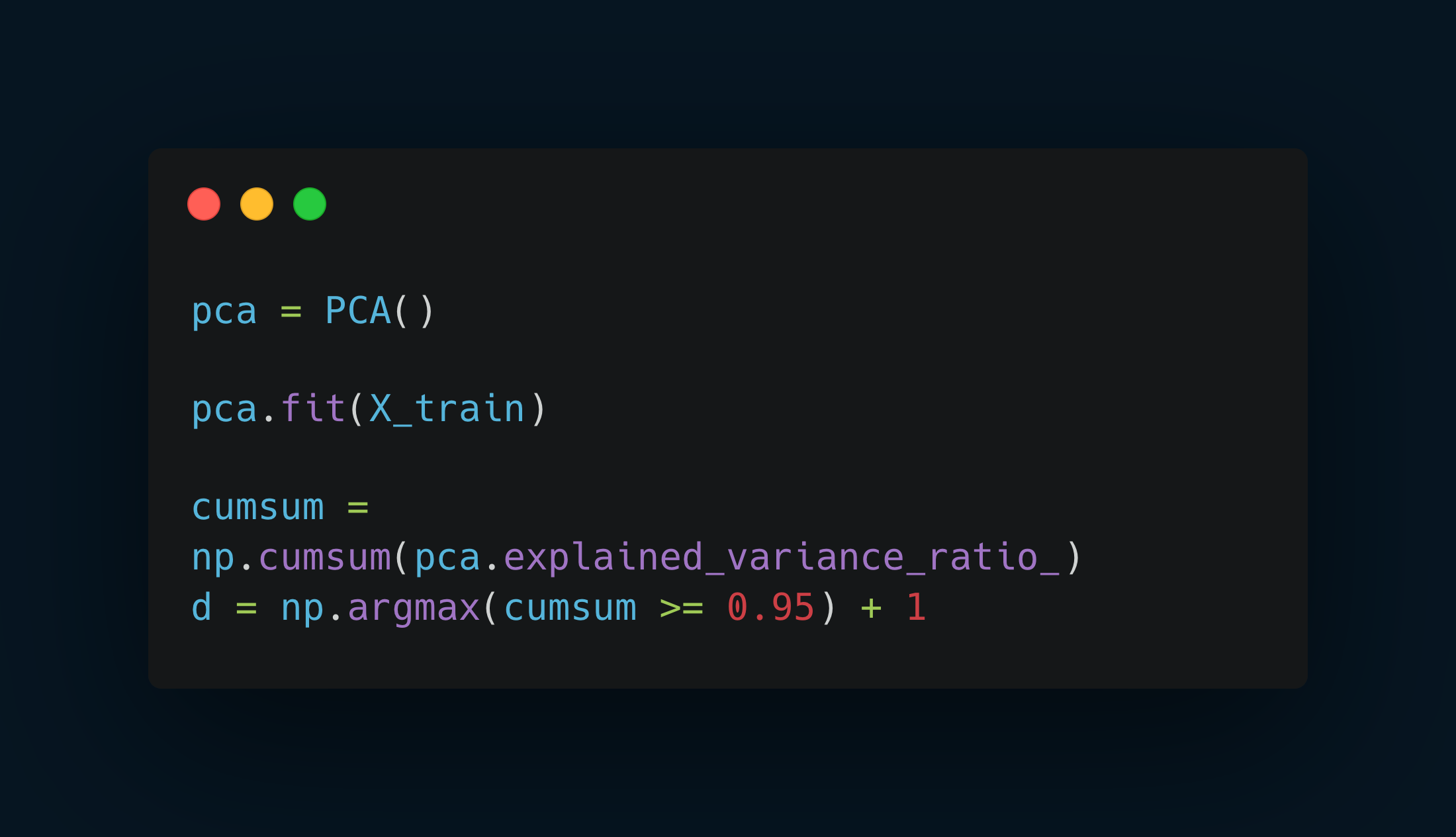
The following code computes PCA without reducing dimensionality. Then computes the minimum number of dimensions required to preserve 95% of the training set’s variance.
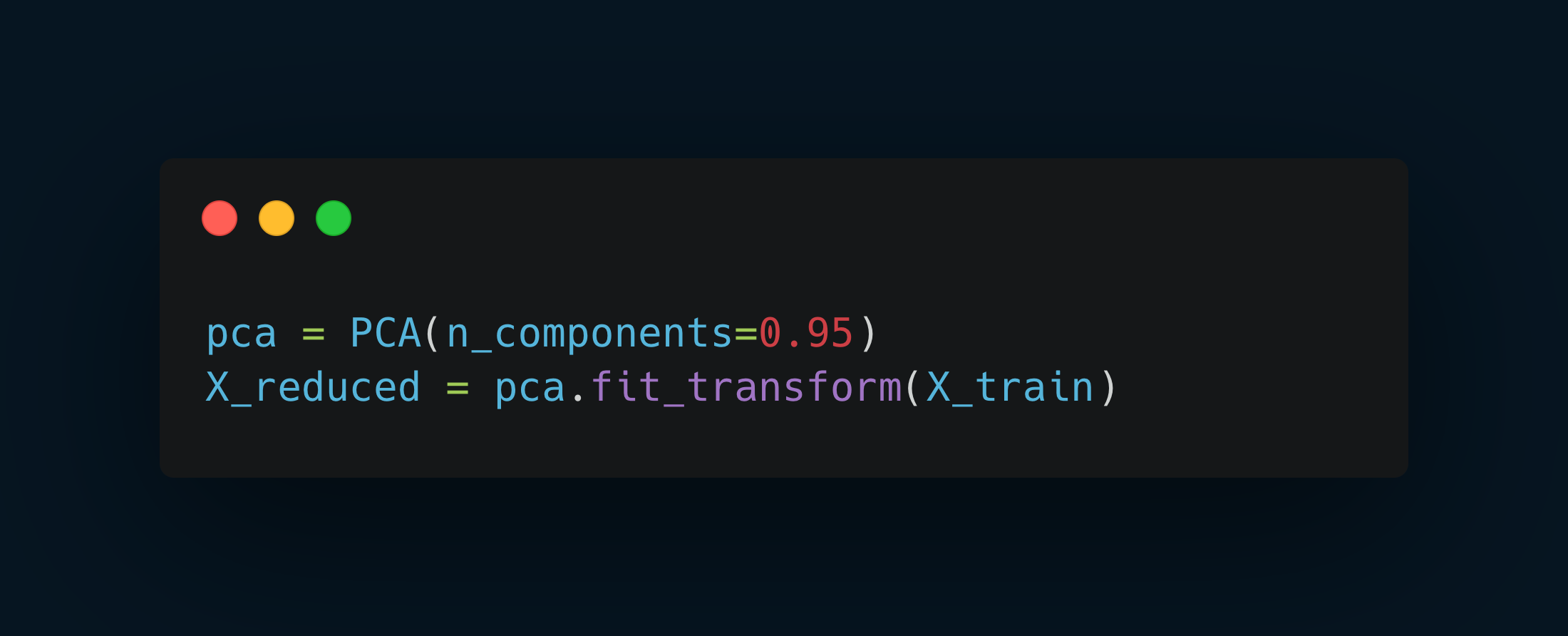
You can simply set n_components as a float between 0.0 and 1.0 to specify the ratio of variance you want to preserve, rather than choosing the number of principal components.
Balancing the Trade-Offs in Dimensionality Reduction
Dimensionality reduction is a balancing act.
While it offers benefits like increased computational efficiency and noise reduction, it also comes with potential drawbacks.
Loss of information and decreased interpretability are significant concerns.
Moreover, the complexity of transformation and the risk of overfitting cannot be ignored.
The Reversibility in Dimensionality Reduction
While reversing dimensionality reduction is theoretically possible, especially with linear methods like PCA, it's often imperfect.
Non-linear methods and autoencoders present additional challenges, making exact reconstruction difficult, if not impossible.
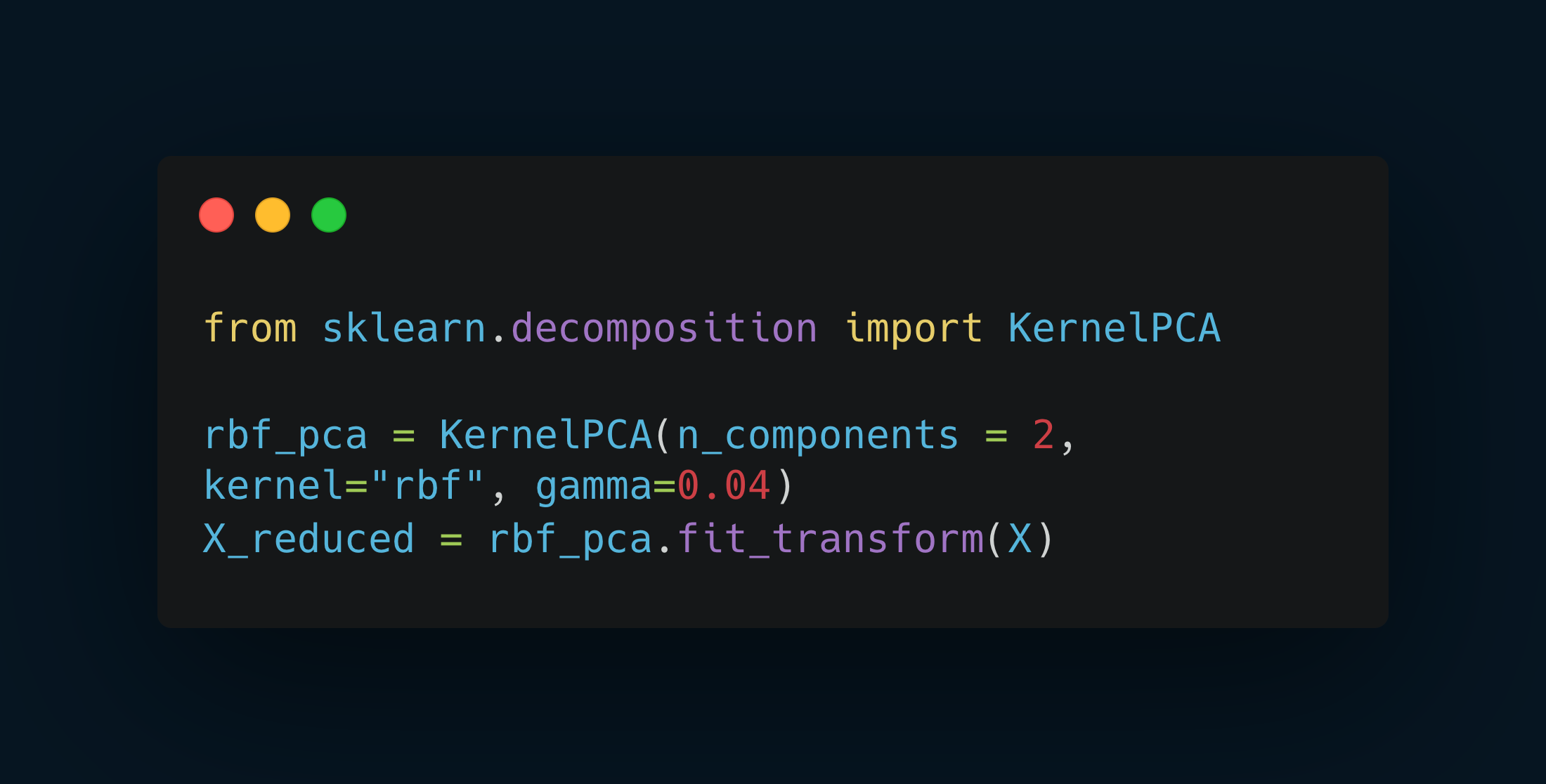
PCA with Nonlinear Datasets
Although PCA is inherently linear, its adaptation, Kernel PCA, can tackle nonlinear datasets.
It leverages the kernel trick to uncover linear relationships in a transformed higher-dimensional space, thus extending PCA's utility to nonlinear contexts.
Conclusion
In conclusion, dimensionality reduction is an indispensable tool in machine learning.
It simplifies complex datasets, making them more manageable and understandable.
While it has its limitations and challenges, its benefits in terms of computational efficiency, performance enhancement, and data visualization are undeniable.
Whether through projection or manifold learning, algorithms like PCA play a pivotal role in transforming data into a format where patterns can emerge and insights can be gleaned.




