
A Comprehensive Guide to Stratified K-Fold Cross-validation for Unbalanced Data


Introduction
Have you ever found yourself in a situation where your machine learning model struggles to perform well on classes with fewer samples?
It's a scary scenario because some classes dominate others, skewing your model's ability to learn fairly from all available information.
If so, you're not alone.
Many real-world datasets suffer from class imbalance, where some classes are underrepresented compared to others.
This imbalance can severely impact the performance of your models, leading to biased predictions and inaccurate results.
Fear not!
Stratified K-Fold cross-validation might be the solution you're looking for.
This advanced validation technique is crucial for datasets with an unbalanced distribution of classes, ensuring each class gets fair representation in both training and validation phases.
Let's dive deeper into what makes Stratified K-Fold cross-validation a cornerstone for developing robust machine learning models.
What is Stratified K-Fold Cross-Validation?
Stratified K-Fold Cross-Validation is an advanced form of cross-validation that is particularly useful when working with datasets that have an unbalanced distribution of classes.
It's a technique that ensures that each fold of the dataset contains approximately the same percentage of samples of each class as the complete set, making the training and validation process fair and more reliable.
The Problem with Imbalanced Data
Standard K-Fold cross-validation, while a robust method for many scenarios, randomly divides the dataset into K equal-sized folds. This randomness does not guarantee the representation of minority classes in each fold.
This could severely impact the model's ability to learn and generalize about those minority classes, leading to biased or inaccurate models.
How Stratified K-Fold Cross-Validation Works
Stratified K-Fold Cross-Validation addresses this issue by ensuring that each fold is a good representative of the whole dataset.
It works by preserving the original distribution of classes in each fold, ensuring that the proportions between classes are conserved.
This approach makes sure that each class is adequately represented across all folds, allowing for a fair and accurate evaluation of the model's performance.
The Step-by-Step Process
Order Samples Per Class: First, the samples in the dataset are ordered by class, grouping all samples belonging to the same class together.
Creating Strata: For each class, the samples are divided into K non-overlapping sets or strata. It ensures each class is proportionally represented in every fold. These strata are created in such a way that the number of samples in each stratum is approximately equal, or as close as possible if the class size is not divisible by K.
Combining Strata into Folds: The stratified folds are then created by taking the first stratum from each class and combining them into the first fold, the second stratum from each class into the second fold, and so on. This way, we form folds that reflect the dataset's original class distribution.
Perform K-Fold Cross-Validation: The K-Fold Cross-Validation process is then carried out as usual, with one fold serving as the test set and the remaining K-1 folds used for training in each iteration.
By using Stratified K-Fold Cross-Validation, the model's performance is evaluated on a more representative sample of each class, even when dealing with imbalanced data.
This helps to mitigate the bias that can arise from having underrepresented classes in the test set and provides a more reliable estimate of the model's overall performance.
Implementation in Scikit-Learn
Scikit-Learn, the popular Python machine learning library, provides built-in support for Stratified K-Fold Cross-Validation.
Here's an example of how you can implement it using the StratifiedKFold class:
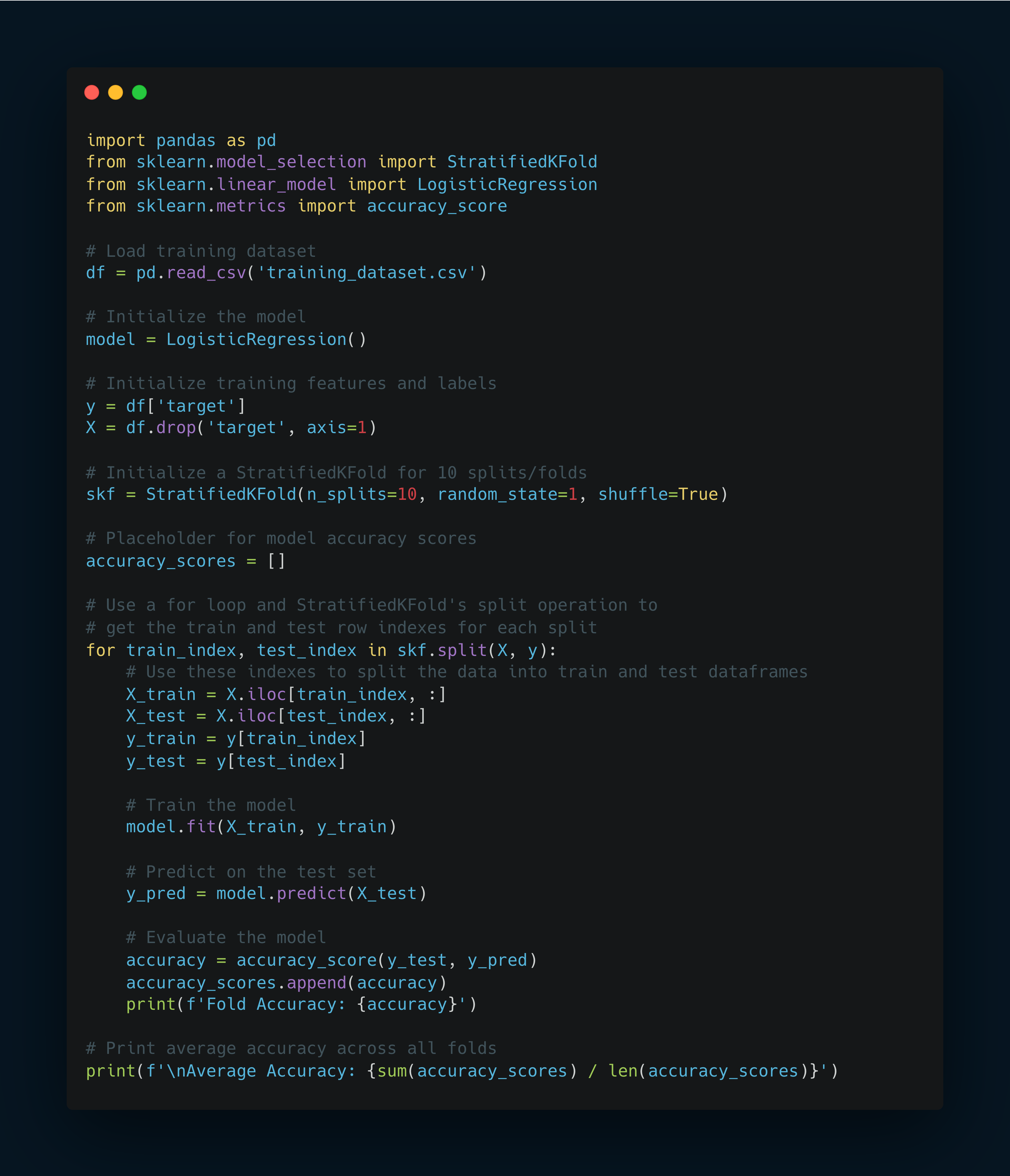
In this example, we first load the training dataset and initialize the model and training features/labels.
We then initialize a StratifiedKFold object with 10 splits and set shuffle=True to ensure that the data is shuffled before splitting.
Next, we use a for loop and the split method of the StratifiedKFold object to get the train and test row indexes for each split.
We then use these indexes to split our data into train and test dataframes, train the model on the training data, and evaluate the model on the test data.
By using Stratified K-Fold Cross-Validation, we can ensure that our model is trained and evaluated on a representative sample of each class, even in the face of imbalanced data.
This approach helps to mitigate the bias that can arise from having underrepresented classes in the test set and provides a more reliable estimate of the model's overall performance.
Conclusion
In the world of machine learning, dealing with imbalanced datasets can be a daunting challenge.
However, with Stratified K-Fold Cross-Validation, you now have a powerful tool in your arsenal to ensure fair and accurate model evaluation, even when some classes are underrepresented.
By preserving the original class distribution in each fold, Stratified K-Fold Cross-Validation guarantees that your model is trained and tested on a representative sample of each class, mitigating bias and improving overall performance.
Whether you're working on medical diagnosis, fraud detection, or any other classification task with imbalanced data, Stratified K-Fold Cross-Validation is a game-changer that can take your models to the next level.
So, embrace this technique, and unlock the true potential of your machine learning models, even in the face of unbalanced datasets.
If you like this article, share it with others ♻️
Would help a lot ❤️
And feel free to follow me for articles more like this.