Decision Trees: Titans of simplicity & power

Senior AI Engineer | Building & Telling Stories about AI/ML Systems | Software Engineer
Imagine a decision-making process so intricate yet robust that it mimics the depth of human reasoning: this is the realm of Decision Trees in Machine Learning.
Imagine a decision-making process so intricate yet robust that it mimics the depth of human reasoning: this is the realm of Decision Trees in Machine Learning.
They are the champions of both classification and regression tasks, striking that delicate balance between simplicity and interpretability alongside robust performance.
They give us accuracy at the expense of transparency or vice versa
Let's dig deeper and find out what makes Decision Trees stand tall in the forest of algorithms.
The Versatile Craft of Decision Trees
They handle classification, where categorizing data into discrete classes is necessary, and regression tasks, where predicting continuous outcomes is key.
But their talent doesn't end there—they handle multi-output tasks with the same ease.
Imagine a tree where each branch represents a choice and each leaf the outcome; that's a Decision Tree in essence.
But it’s more than just about reaching conclusions; it's about understanding probabilities.
Decision Trees elegantly estimate the likelihood of each class, giving us not just an answer, but a measure of certainty.
Training Algorithms
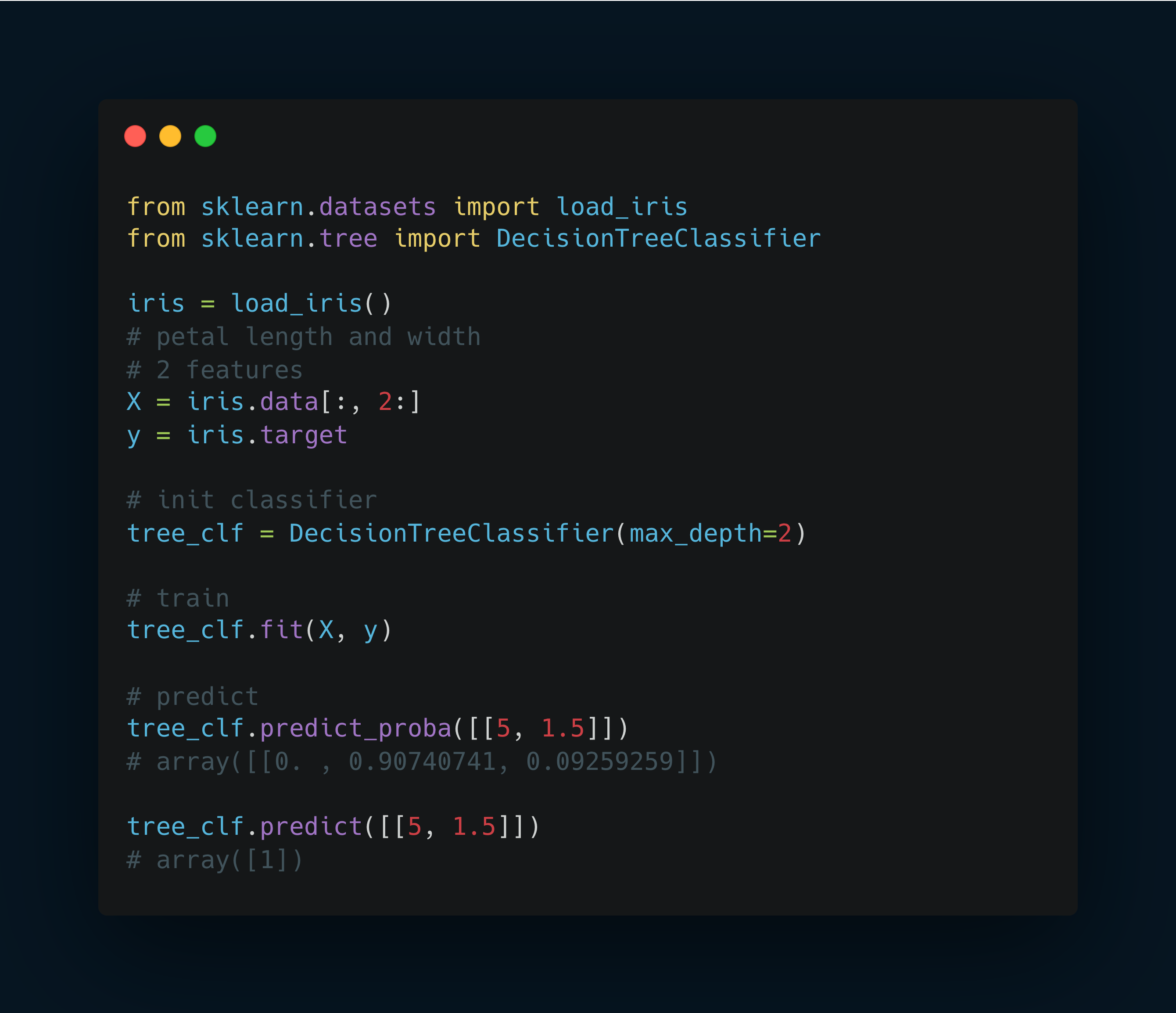
The CART (Classification And Regression Tree) algorithm is used to train a Decision Tree.
The algorithm starts by splitting the data and choosing the most effective feature and threshold. It’s all about purity; the best-split yields the most homogeneous subsets.
From there, it branches out recursively, seeking the purest subsets at every turn.
From there, it branches out recursively. The algorithm splits the data further, seeking the purest subsets at every turn.
This greedy approach may not always lead to a perfect tree, but it does grow a decisively good one.
It tries to find the best immediate split without pondering the downstream effects, which sometimes leads to suboptimal solutions.
Nevertheless, the resulting decision tree is surprisingly close to the best possible model.
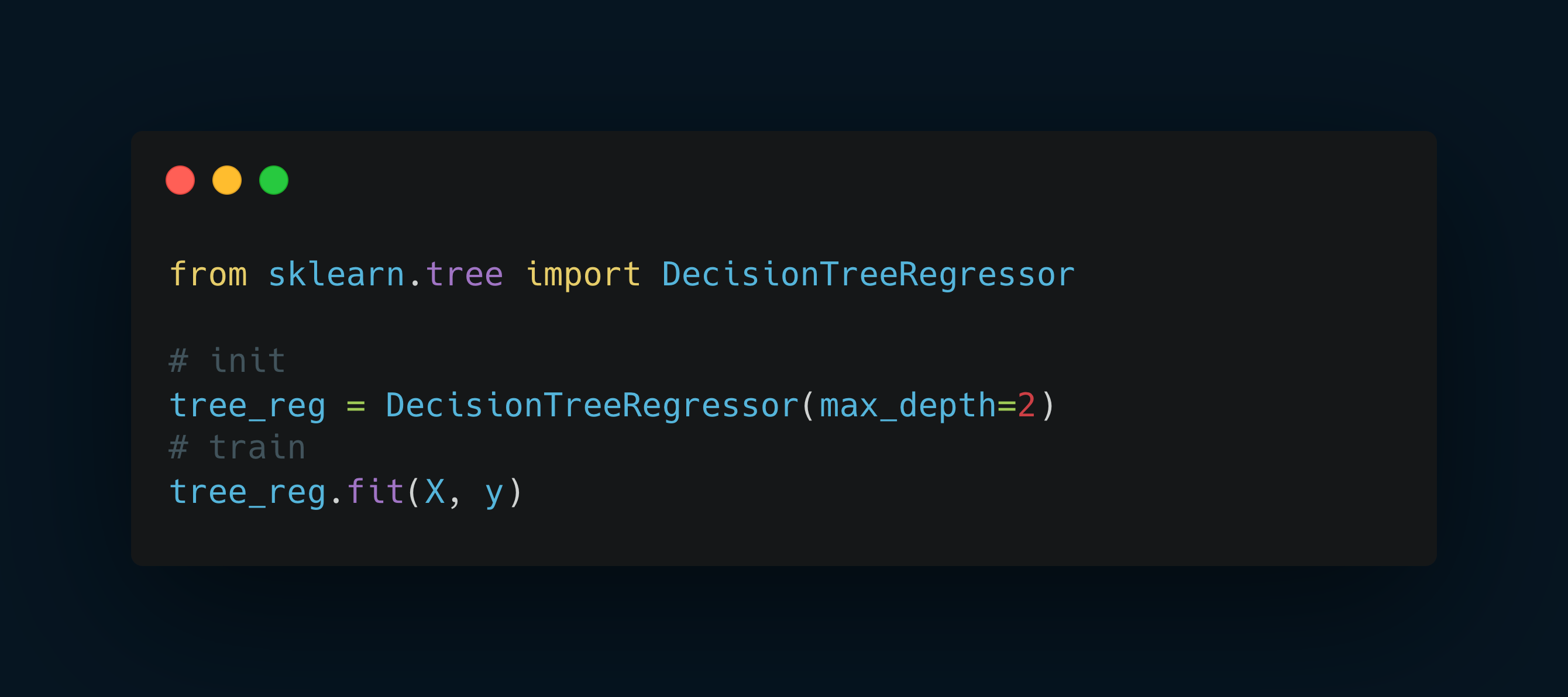
The Subtleties of Regression Trees
When it comes to regression, the CART algorithm adapts.
Instead of seeking the purest split, it minimizes the Mean Squared Error (MSE).
The approach shifts subtly, like changing fertilizers to suit a different plant, ensuring that the growth—our predictions—is as close to the actual values as possible.
Computational Complexity
The training algorithm compares all features on all samples at each node. So, the complexity is O(n × m log(m)).
But once trained, Decision Trees are generally approximately balanced. Making predictions is swift, requiring going through O(log2(m)) nodes. So, the overall prediction complexity is just O(log2(m)), independent of the number of features.
Avoiding overfitting
If the Decision Tree is left unconstrained, then it will adapt itself to the training data, and most likely overfit it.
To avoid overfitting the training data, we need to regularize the model.
Regularization hyperparameters shape the tree to ensure it doesn't mirror the training data too closely.
Generally, we restrict the maximum depth of the Decision Tree.
Reducing max_depth will reduce the complexity of the tree acting as a regularization technique, thus avoiding the risk of overfitting.
In Scikit-Learn, this is controlled by the max_depth hyperparameter (the default value is None, which means unlimited).
Other parameters to tune:
Increase min_samples_split, min_samples_leaf, min_weight_fraction_leaf hyperparameters.
Reduce max_leaf_nodes, max_features hyperparameters will regularize the model.
Avoiding underfitting
Scaling the input features won't get to the root of the problem since Decision Trees are scale-invariant.
Instead, consider giving your tree more freedom to grow by relaxing some hyperparameters such as adding depth.
A Real-World Glimpse
Let's address some practical questions to ground these concepts.
An unrestricted Decision Tree can grow deep; imagine a tree trying to touch the sky. For a million instances, it could grow just as wide, branching out until every single instance is its own leaf.
If a Decision Tree has grown too complex, mirroring every twist of its training data, reducing max_depth is indeed a wise choice. It's the art of restraint, ensuring that the tree is strong and healthy, not tangled in overgrowth.
Conversely, when a Decision Tree is too simple, it may miss the forest for the trees, so to speak.
But simply scaling the input features is not the answer—it’s not about the size of the branches but how well they connect to form a coherent structure.
Instead, allowing the tree to grow deeper or more complex may provide a better view of the forest.
Code examples
Conclusion
Decision Trees are like the wise old sages of Machine Learning — simple, yet profound.
They teach us that often the most powerful solutions come from clarity and a methodical approach to problem-solving.
Are you ready to branch out with Decision Trees in your next Machine Learning project?
Share your thoughts below!
If you like this article, please share it with others♻️
That would help a lot ❤️




